

Recently, I have been spending a lot of time on one question: how far can we push the limits of a table format on object storage?
Object storage gives us cheap, durable bytes and a few nice atomic primitives, but it does not give us database-style transaction throughput. One of the distinct characteristics of table formats is that they build atomic transactions on top of object storage and provides MVCC-style ACID guarantees. This is a hugely important feature, but it is also a curse: ultimately, how fast a table format can commit is bounded by what object storage can handle.
While I believe LanceDB and the Lance format have found a way to break this curse (and get ready for me to publish more blogs on this story in the coming days 😆), I wanted to step back and ask whether we have truly extracted everything we can from what object storage-based table commit offers today. The answer is easiest to get by comparing the three dominant shapes of table metadata — Delta Lake, Apache Iceberg, and Lance — and conducting a real benchmark. I will start with the design details, and then get to the benchmark details and analysis.
How Table Formats are Designed
Delta Lake, Iceberg, and Lance all fundamentally solve the same problem: atomically publish a new table version as metadata, then give readers a format-defined way to discover and load the latest version. Where they diverge is in where the cost goes: Delta Lake writes a log and periodically checkpoints it, Iceberg publishes a catalog pointer to a metadata tree, and Lance publishes a compact versioned manifest with transaction details tied to it.
Delta Lake: versioned JSON log and Parquet checkpoint
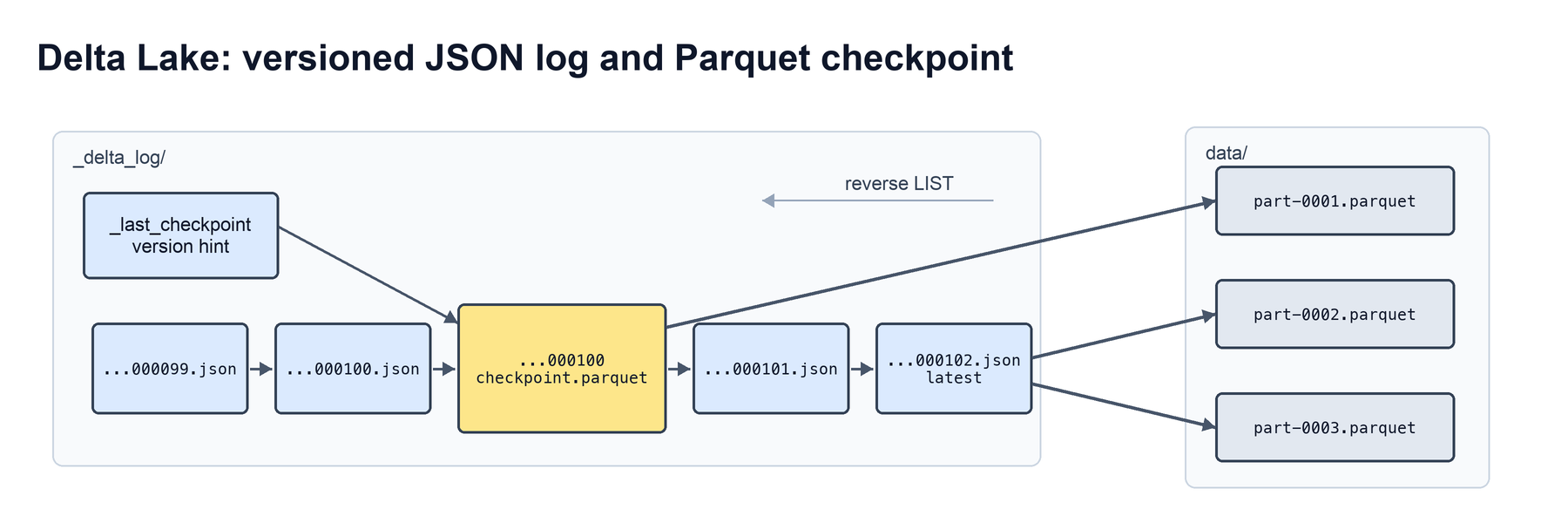
In Delta Lake, each commit writes a new JSON file in _delta_log, and periodic checkpoints summarize the active table state so readers do not need to replay the whole history. In theory, this makes the write path extremely fast: a commit can be just one small log entry describing what changed.
The tradeoff is that the latest table state is not naturally stored as a single object. It is reconstructed from a checkpoint plus the tail of the log. If checkpoints are too infrequent, readers pay more log replay. If checkpoints are frequent, writers periodically pay checkpoint creation.
In managed Delta deployments, checkpoint creation can also be moved out of the foreground write path. That gives the system an appealing amortized shape: commits stay close to log-only writes, while reads are bounded by replaying only the log entries since the last checkpoint.
Iceberg: catalog pointer, JSON metadata, and Avro 2-level manifests
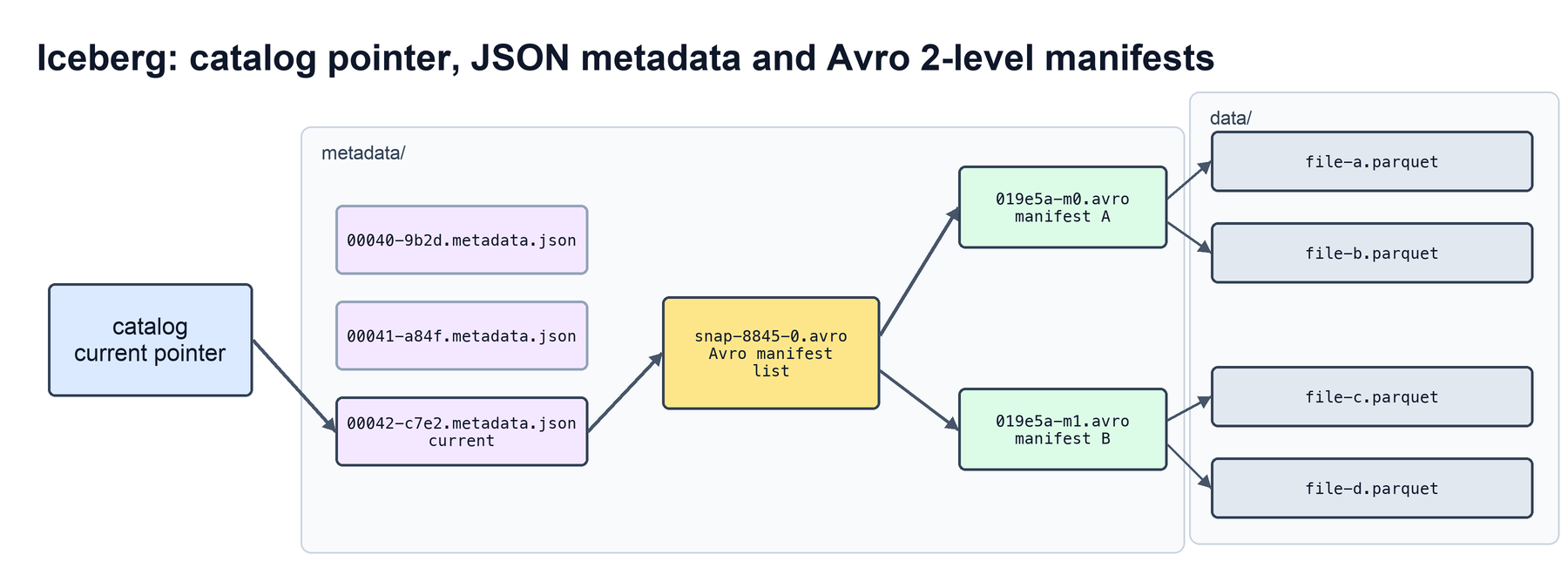
Iceberg makes a different tradeoff: it publishes a complete snapshot, so loading the latest table state is straightforward, but each commit has to write and publish a larger metadata tree. A typical write produces manifests, a manifest list and a JSON metadata file, then relies on the catalog commit to make that metadata file current. The reader does not need to replay a log; it can read the published snapshot and start planning from there.
Iceberg also puts retained snapshot history into the latest table metadata JSON. In that sense, the role Delta Lake spreads across _delta_log/ log files becomes encapsulated in Iceberg’s current metadata file: the latest JSON metadata points to the current snapshot and also carries historical snapshot and metadata-log information.
The 2-level manifest tree is designed for planning scalability: large tables can spread metadata across many manifests, allowing planners to handle millions of files without treating the active file list as one giant object.
Lance: versioned Protobuf manifest and transaction
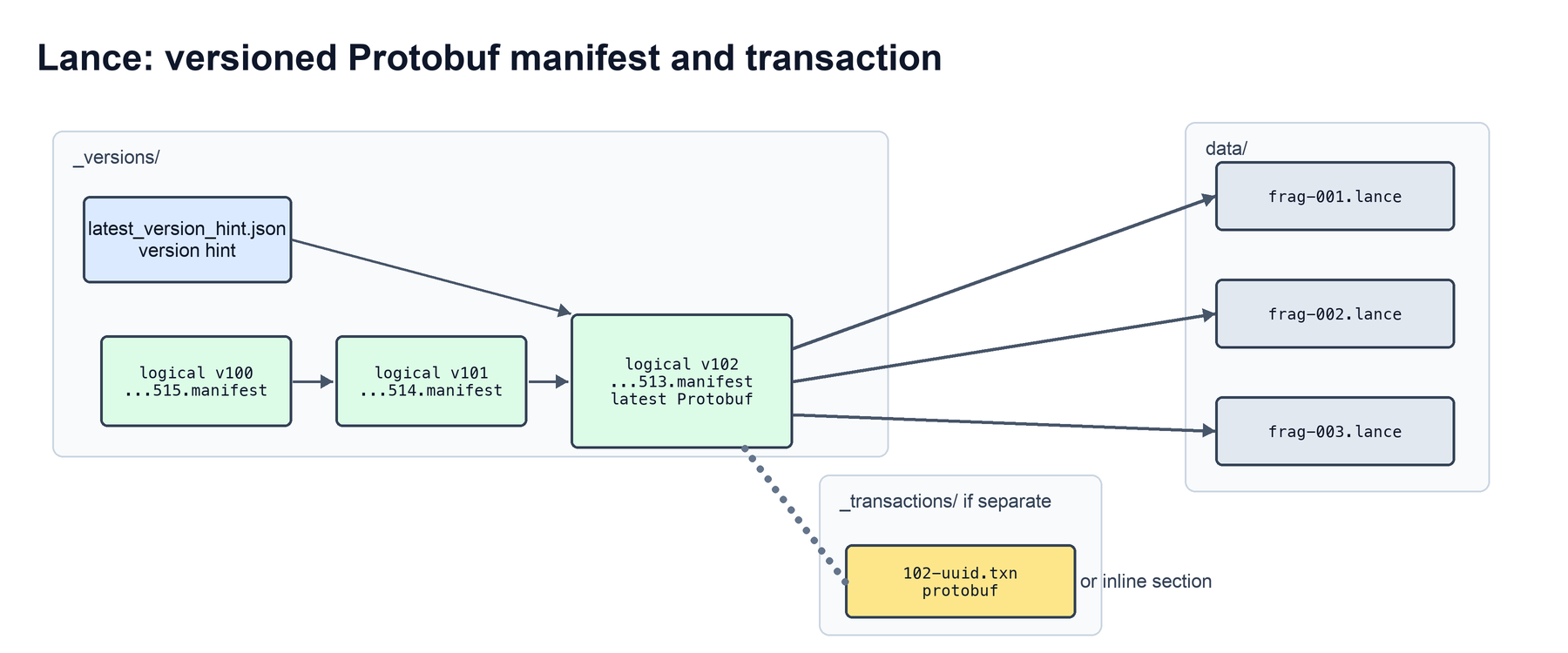
Lance sits between the two designs. The latest manifest is a compact protobuf snapshot of the current table state, so a reader does not need to replay a log. The transaction that produced the version is stored in the manifest itself, or in a separate protobuf file under _transactions/ when it is too large to inline.
This gives Lance an Iceberg-like property: the latest table state is directly readable as a snapshot. But Lance does not copy full historical table metadata into the latest manifest. This is where Lance is closer to Delta Lake: history is represented by versioned metadata files, similar to Delta Lake’s _delta_log/ directory. Old manifests remain available for time travel, but opening the latest table does not require reading them.
The manifest is encoded with protobuf instead of JSON. For this path, metadata is machine-to-machine state: a reader fetches the manifest object, decodes it directly, and gets the data file pointers needed for planning.
Lance names manifest files so newer versions sort first in reverse lexicographical order. A reader can discover the latest manifest with a bounded listing pattern instead of scanning the full version history. This lets a table keep old versions for time travel without making every latest-version open walk through all of them.
Lance also maintains a best-effort version hint file that records a possible latest version of the table, which is typically written after a commit has succeeded. When resolving the latest version, Lance runs two paths in parallel and returns the faster valid result: (1) a LIST against the _versions directory, and (2) GET of the version hint followed by multiple parallel HEAD requests. The LIST bounds the maximum possible version visible at that point in time, while the HEAD requests keep the fast path fast by checking likely latest versions directly.
Benchmark setup
I ran three metadata-focused benchmarks on S3 and S3 Express. The first measured metadata commit latency during 10,000 sequential append commits. The second measured metadata load latency, where each step loads the metadata of a version of the table during the 10,000 commits. The third measured concurrent commit throughput with many writers appending to the same table.
Note on Iceberg catalog choice
At least today, there is no officially supported and widely adopted storage-only Iceberg commit path in the same sense as Lance or Delta Lake. Iceberg’s commit protocol is catalog-mediated: the table metadata tree is written to object storage, then a catalog atomically publishes the latest metadata location.
For that reason, I chose to test two commonly used open source Iceberg catalog paths. The first is Postgres through iceberg-rust SqlCatalog, which is the direct catalog baseline and likely the most performant solution for Iceberg. The second is Apache Polaris through the Iceberg REST Catalog, with Polaris backed by Postgres in the same region. This compares Iceberg as it is normally deployed, rather than giving it a storage-only mode that most users do not have.
Benchmark Environment
The benchmarks ran on an Amazon EC2 c7i.48xlarge instance in us-east-1b with S3 bucket in the same region and S3 Express bucket in the same availability zone. A large instance is used to ensure the clients were not CPU-bound for the concurrent commit benchmark.
Benchmark Code Snippets
The relevant harness snippets are available as public gists:
- Metadata commit latency benchmark
- Metadata load latency benchmark
- Concurrent commit throughput benchmark
Results on S3
On standard S3, Lance had the strongest end-to-end profile: the lowest average metadata commit latency, the lowest end-of-run metadata commit latency, the lowest metadata load latency, the smallest active metadata footprint, and the healthiest writer failure rate.
The summary table combines the 10,000-append continuous benchmark with the concurrent writer sweep. The last-100 rows average the final 100 successful appends. The average writer rows average the runs at 10, 20, 50, 100, 120, 150, 180, and 200 writers.
Metadata commit latency
The metadata commit curve shows a clear pattern over time. Average metadata commit latency was 140 ms for Lance, 534 ms for Delta Lake, 457 ms for Iceberg Postgres, and 583 ms for Iceberg Polaris. In the final 100 commits, Lance averaged 168 ms, while Delta Lake reached 926 ms, Iceberg Postgres reached 661 ms, and Iceberg Polaris reached 928 ms.
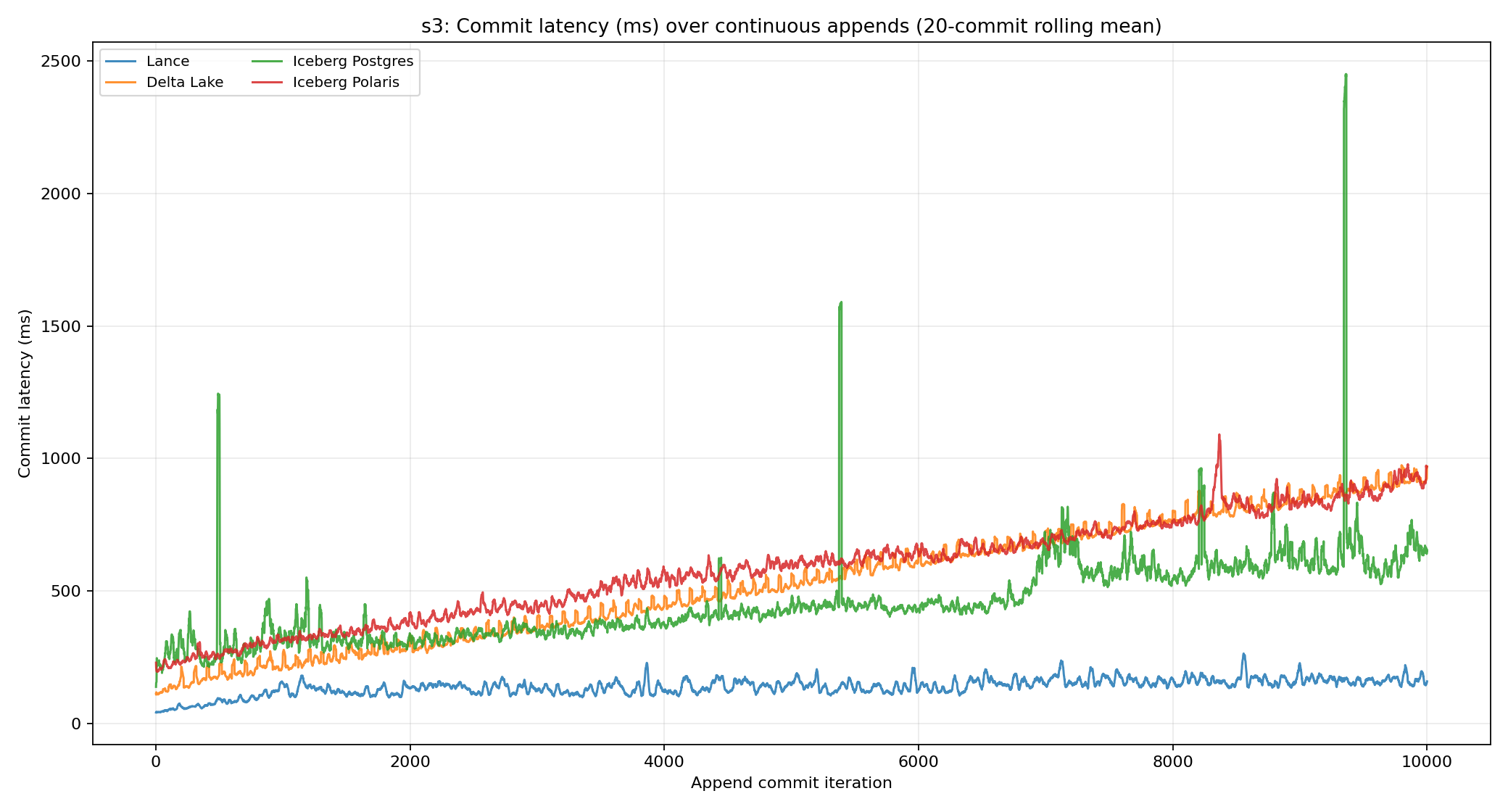
Why Lance is the best performer
Lance is the fastest here because its metadata write path scales with the right variable. A Lance commit writes a latest manifest whose size grows with the number of files tracked in the current table state, not with the number of historical commits. That is the same high-level shape Delta Lake gets from checkpointed active state, but Lance stores that state directly in a compact protobuf manifest.
The manifest is also small because Lance does not write unnecessary statistics into core table metadata. For search and training workloads with random-access read patterns, those statistics are usually not useful on the hot metadata path. When an application needs OLAP-style pruning, the same information can be built as a secondary zonemap index instead of being forced into every commit.
These numbers measure active latest-state metadata, not all retained historical metadata. After 10,000 appends, the active metadata required to open the latest state was:
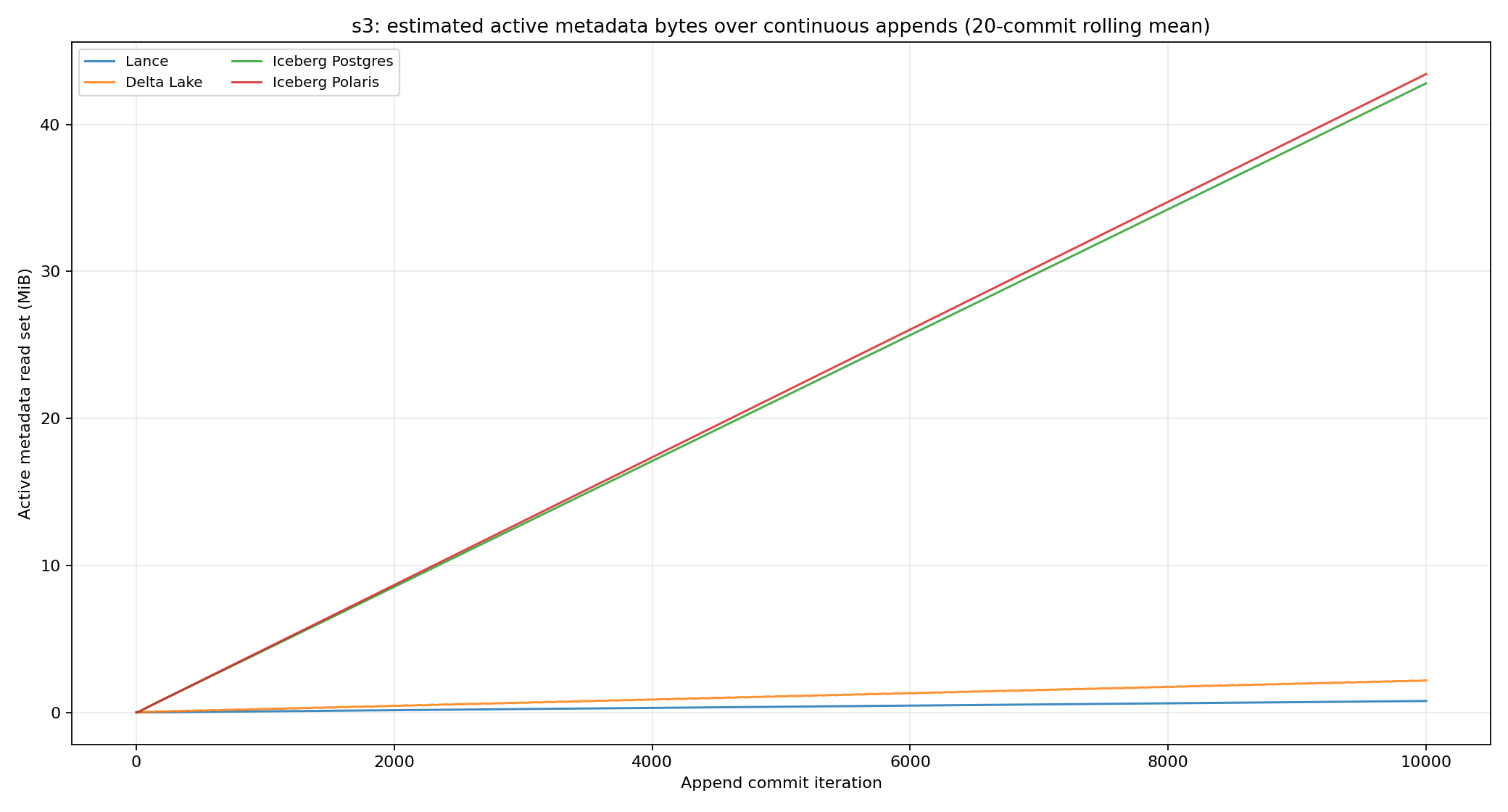
Why Iceberg commit latency grows
Iceberg’s upward trend and large metadata footprint are expected. Every append publishes a new metadata JSON file. That file carries table-level state, including retained snapshot history, the snapshot log, the metadata log, and references to the current metadata tree. As a result, the metadata JSON written on each commit grows with the number of commits.
The append also produces or references manifest state and then asks the catalog to atomically swap the current metadata pointer. Even if the catalog commit itself is a single pointer update, the object storage work below it is not constant-size.
Iceberg also carries a larger active metadata tree overall. The 2-level manifest design is useful for planning across millions of files, but the active latest-state read set generally contains more metadata files and more metadata bytes than a compact flat list. The same design adds write-side metadata work: an append may need to produce a manifest, a manifest list, and the metadata JSON file that the catalog publishes.
This is why the Iceberg V4 single-file commit work is important. It moves Iceberg toward a single-file commit pattern more similar to Lance and Delta Lake.
Why Delta Lake commit latency was unexpectedly high
The surprising result is Delta Lake. In theory, Delta Lake should be extremely fast if you only count the log write. With the default behavior of one checkpoint every 100 writes, I expected it to be faster than Lance most of the time, except when a checkpoint had to be written. To understand the gap, we patched the Rust path to decompose commit time into log-only work, log plus checkpoint work, and the full table update path.
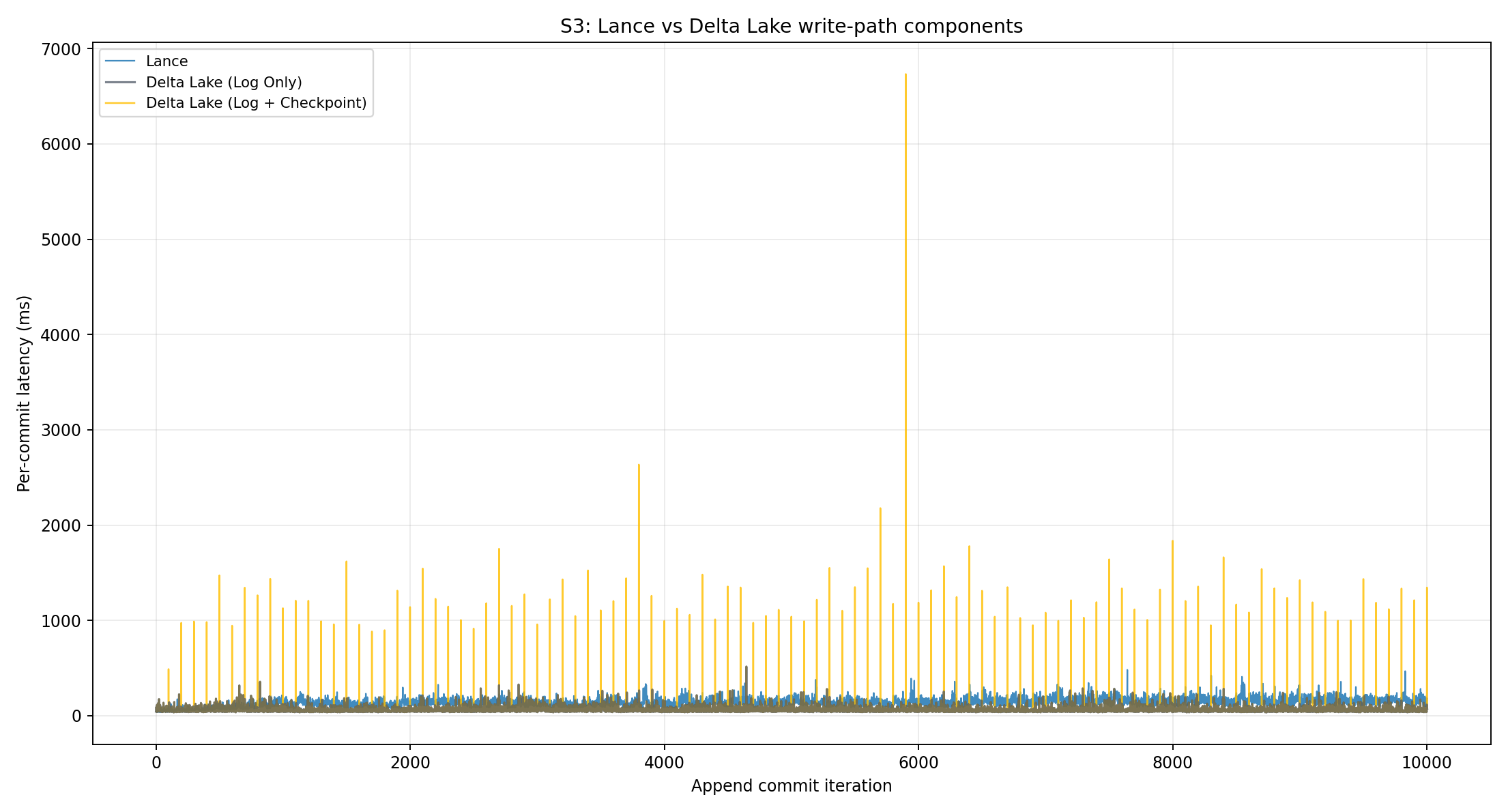
The patched numbers confirmed the theory: Delta Lake log-only averaged 64.5 ms and stayed mostly constant, as expected. Checkpointing happens by default every 100 commits and creates large spikes, but the checkpoint write time was also mostly constant. It did not explain the linear latency growth.
The issue is that the Delta Lake kernel post-commit path also updated the snapshot and materialized active file state in memory to prepare for subsequent reads or checkpoint writes. That work grew with the number of versions and files, and was the main source of the linear latency growth.
This is the core tradeoff. Delta can make the immediate log write small, but good read performance needs checkpointing and materialized file state. If that compensation happens on the write path, the full commit is no longer just “write one JSON file.” If it is deferred, the next reader pays.
Metadata load latency
Metadata load latency showed the bigger separation. At the end of the run, Lance reopened the latest table in about 199 ms. Delta Lake was about 695 ms. Iceberg Postgres and Iceberg Polaris were both over 6 seconds.
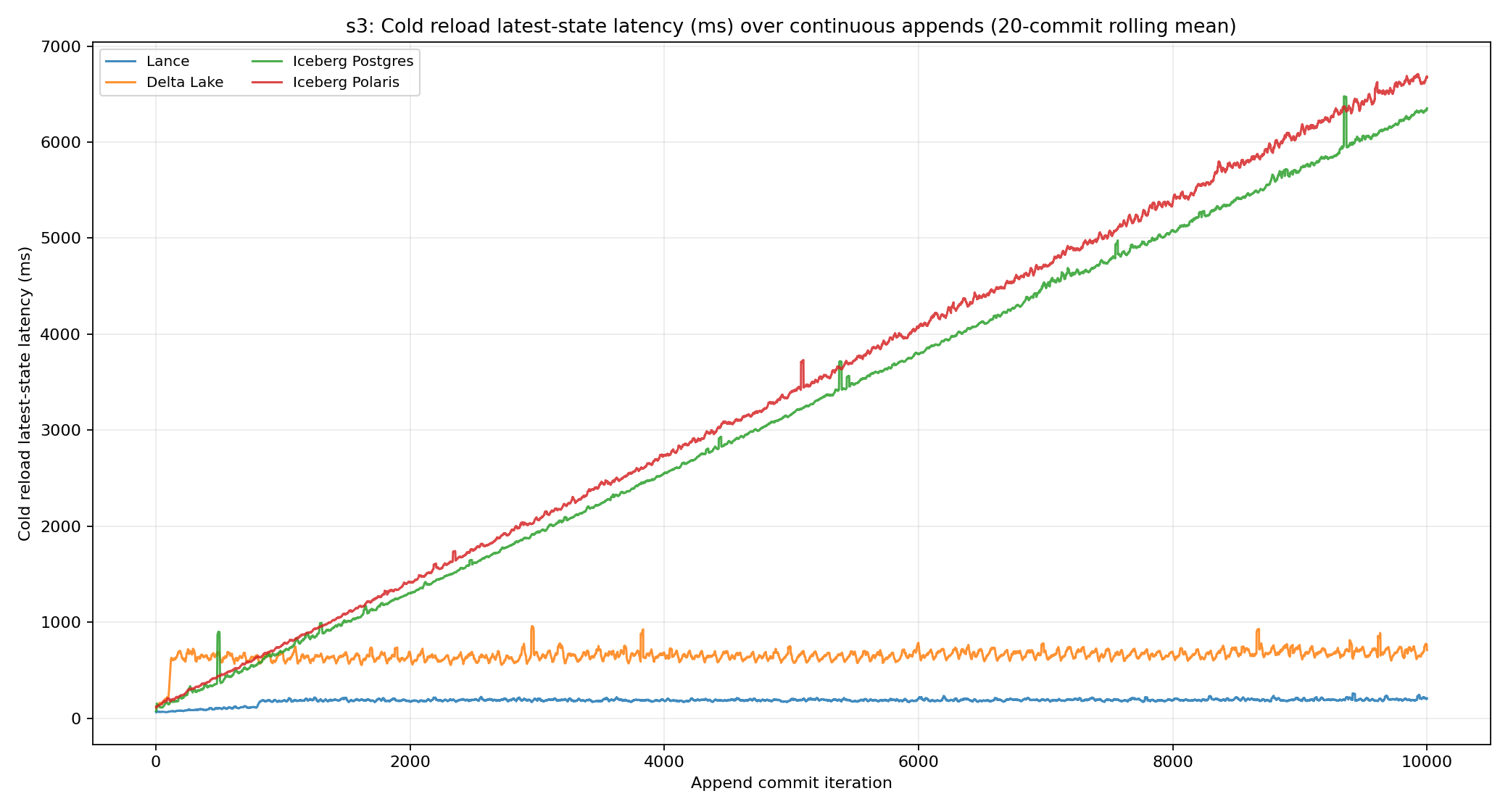
Why Lance is the best performer
Lance load latency is low for the same reason commit latency is low: the latest table state is one compact protobuf manifest, and latest-version discovery is bounded. A fresh open does not replay a log, walk retained historical metadata or ask a catalog to resolve the current metadata pointer. It finds the latest manifest, decodes it and gets the active data-file pointers needed for planning.
This matters more as the table ages. Delta Lake can use checkpoints to avoid replaying the entire log, but loading still has to reconstruct active file state from the checkpoint and newer log tail. Iceberg can jump directly to the current snapshot, but that snapshot points into a larger manifest tree and a metadata JSON file that grows with commit history. Lance keeps both pieces small: latest-version lookup is bounded, and the active state to decode is compact.
Surprising increased latency of Iceberg Polaris
One surprising detail in the load-latency graph is that Iceberg Polaris was slower than Iceberg Postgres even after accounting for the service-catalog hop. The difference actually came from layout: the default Polaris Iceberg table path was longer than the Postgres path.
Because Iceberg records absolute paths, those extra path bytes appear at every level of the metadata tree and compound into additional metadata size. This is also why Iceberg V4 relative paths are a much-needed feature for the Iceberg community.
Concurrent commit throughput
The concurrent commit throughput test showed why throughput numbers must include failure rate. At 200 writers on S3, Lance sustained 5.5 successful commits/sec with a 16% failed-attempt rate. Delta Lake also reported 5.5 successful commits/sec, but with an 88% failed-attempt rate. Iceberg Postgres reached 4.5 successful commits/sec with a 94% failed-attempt rate. Iceberg Polaris reached 3.1 successful commits/sec with an 89% failed-attempt rate.
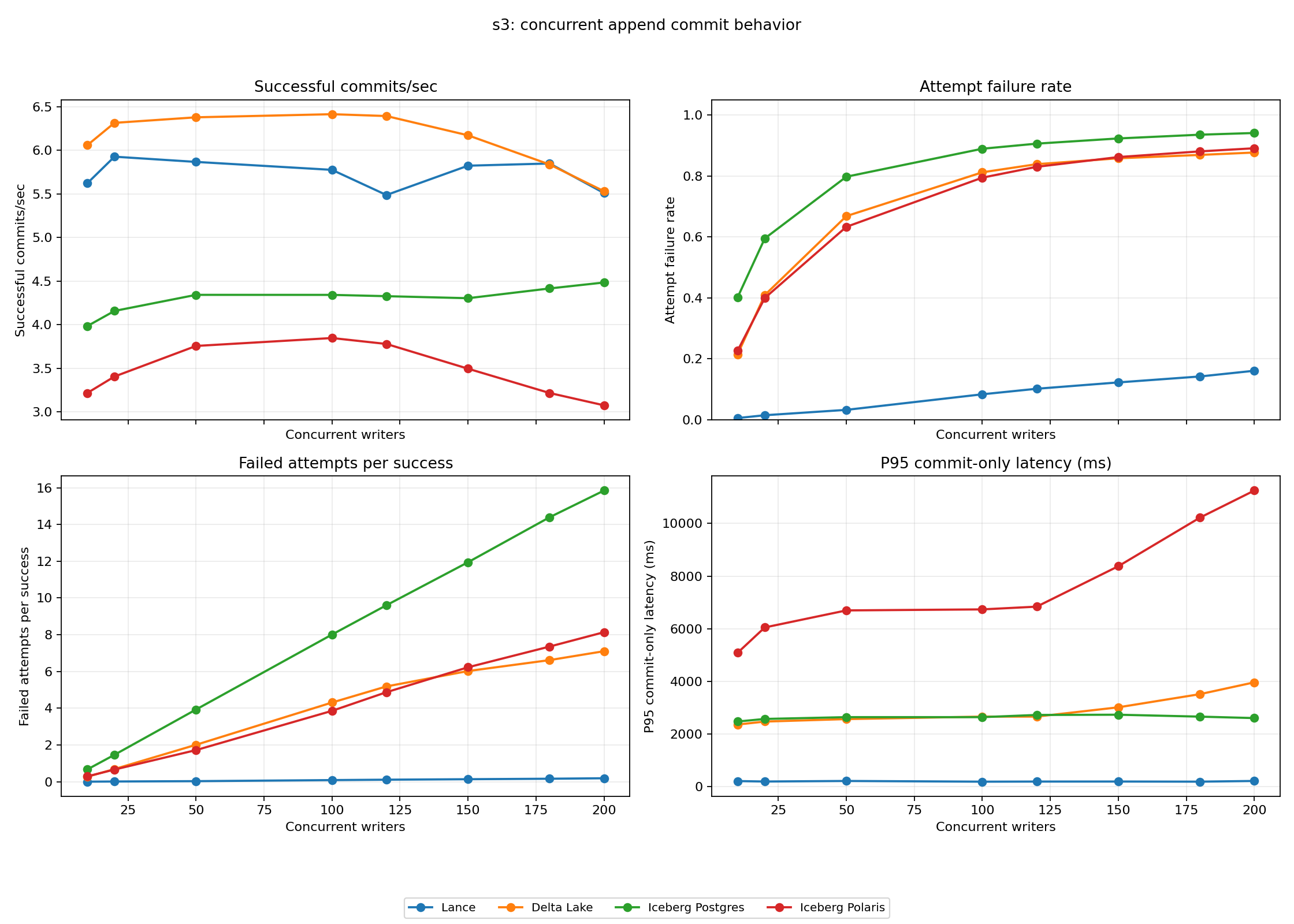
Why Lance is the top performer
Lance is the strongest complete performer here across the full set of metrics. It has the smallest active metadata footprint, the fastest metadata load path, and the fastest full metadata commit path. Those advantages reduce the time each writer spends in the critical path.
The other important signal is waste. At 200 writers on S3, Lance and Delta Lake both reported 5.5 successful commits/sec, but Lance did it with a 16% failed-attempt rate while Delta Lake had an 88% failed-attempt rate. Fewer retries mean fewer wasted object storage requests and less self-inflicted pressure on the same object storage limits. Lance’s retry behavior is also more friendly to object storage because it backs off and adapts instead of continuously amplifying conflicts.
Why Delta Lake can show higher raw throughput
It is expected that Delta Lake can look competitive, or sometimes better, on raw successful commits/sec. Delta Lake still has the fastest core publish primitive: write the next JSON log file. In a concurrent-write benchmark, the post-commit snapshot update and materialization work is less dominant than it is in the sequential per-commit latency chart, because the system is increasingly shaped by conflict races and object storage publish limits.
That advantage diminishes as concurrency rises. More writers race for the same next log version, failed attempts multiply and throughput becomes bounded by object storage request latency and rate limits. At that point, Lance’s lower retry and failure rate becomes the more important property: it reaches comparable successful throughput while generating far less conflict traffic.
Why Iceberg throughput is lower
Iceberg is noticeably weaker than Delta Lake and Lance on throughput, especially when failure rate is included. The key reason is conflict handling. Iceberg commits publish complete snapshots that record the resulting table state, a coarse operation label, and file-level add/delete effects, but they do not preserve a fine-grained transaction intent that can always be replayed against a newer version.
After a conflict, the client has to validate operation-specific assumptions and rebuild a new metadata tree. That is computationally expensive and sometimes not possible for multi-version conflicts across different operation types. In that regime, Iceberg naturally spends more time in failed attempts, validation, and retry, which lowers transaction throughput even when object storage itself is fast.
This benchmark is still a friendly case for Iceberg because every writer is doing a small append. Appends can usually be retried by adding the newly written manifest on top of a newer table state. The issue becomes more visible in production when a table has a mix of appends, overwrites, deletes, compaction, and other metadata operations.
Results on S3 Express
Fast object storage is becoming its own design point. Products such as S3 Express and GCS Rapid are increasingly relevant for agentic and training applications, where the workload can benefit from much faster metadata and data access without always needing the highest availability profile of general-purpose object storage.
The same summary view on S3 Express shows the design gap more clearly. The last-100 rows average the final 100 successful appends. The average writer rows average the full writer-count sweep.
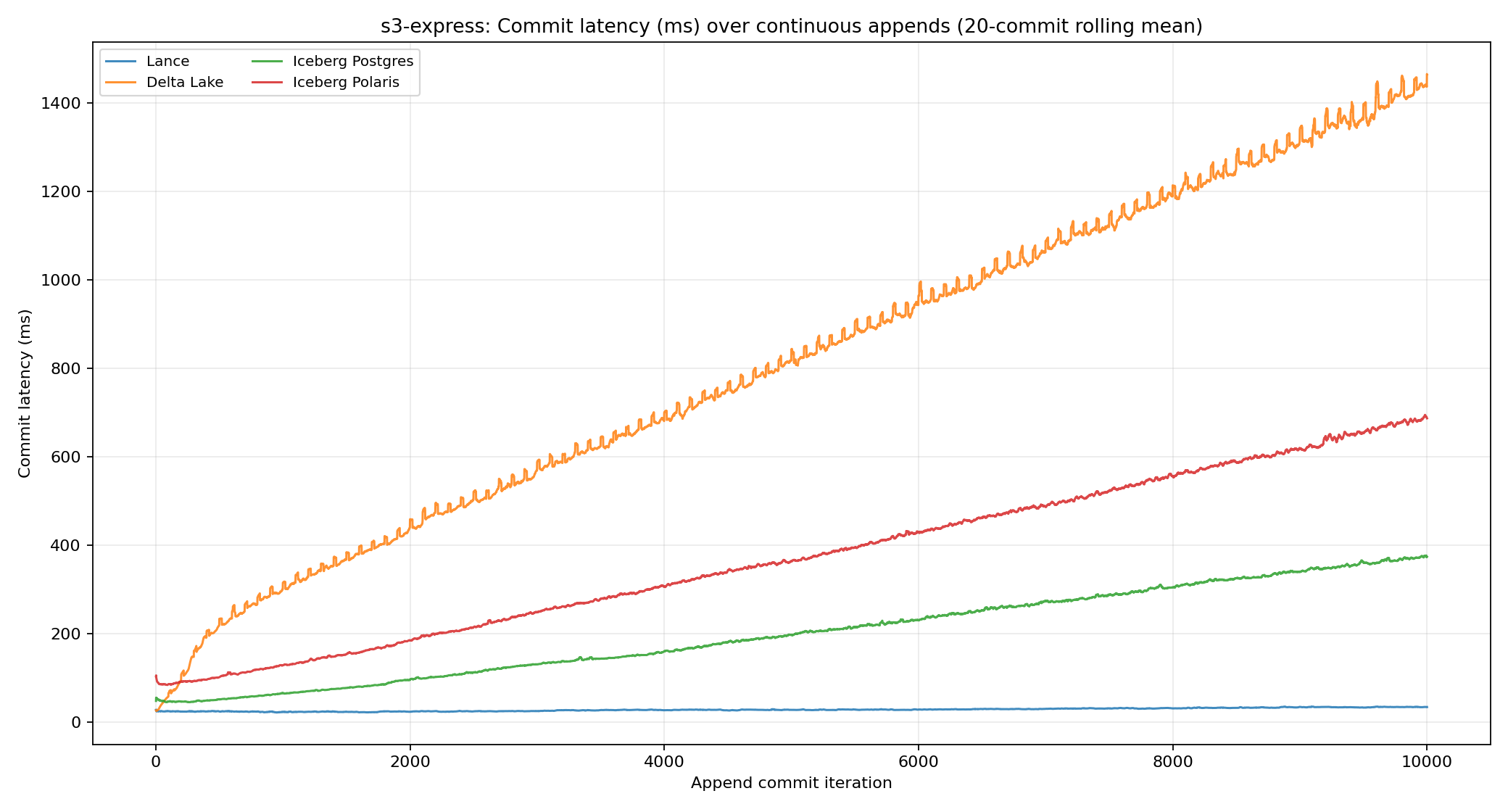
Metadata commit latency
Average metadata commit latency was 27.6 ms for Lance, 811 ms for Delta Lake, 200 ms for Iceberg Postgres, and 372 ms for Iceberg Polaris.
Why Lance is the best performer
S3 Express makes each storage operation faster, but it does not erase metadata design. Lance benefits the most because its commit path is already small: publish a compact protobuf manifest, update the version hint, and let latest-version discovery use bounded LIST plus parallel HEAD probes.
That maps well to low-latency object storage. Lance has fewer bytes to write than Iceberg, no catalog service in the publish path, and no Delta-style post-commit log/checkpoint/materialization work in the full commit path. The result is not just lower average latency; the last 100 commits stayed at 33.6 ms for Lance, compared with 1,441.9 ms for Delta Lake, 373.2 ms for Iceberg Postgres, and 684.9 ms for Iceberg Polaris.
Why Delta Lake performs unexpectedly poorly
Delta Lake was the worst write-time performer on S3 Express. The surprising part is that Delta Lake should have the smallest core commit primitive: write one new JSON log file. The problem is the surrounding log discovery and replay path.
Delta Lake relies on listing _delta_log/ to find and replay the relevant log and checkpoint files. On standard S3, listings are lexicographically ordered, which lets clients bound the work more naturally. S3 Express directory bucket listings are not lexicographically ordered. As a result, the Delta path has to list all contents under _delta_log/ to reliably discover the latest state. That makes the work grow linearly with the number of commits.
This turns a format that should be cheap at write time into the worst performer in this S3 Express benchmark. Faster per-request latency helps, but it does not fix a path that needs an ever-larger directory listing as the commit history grows.
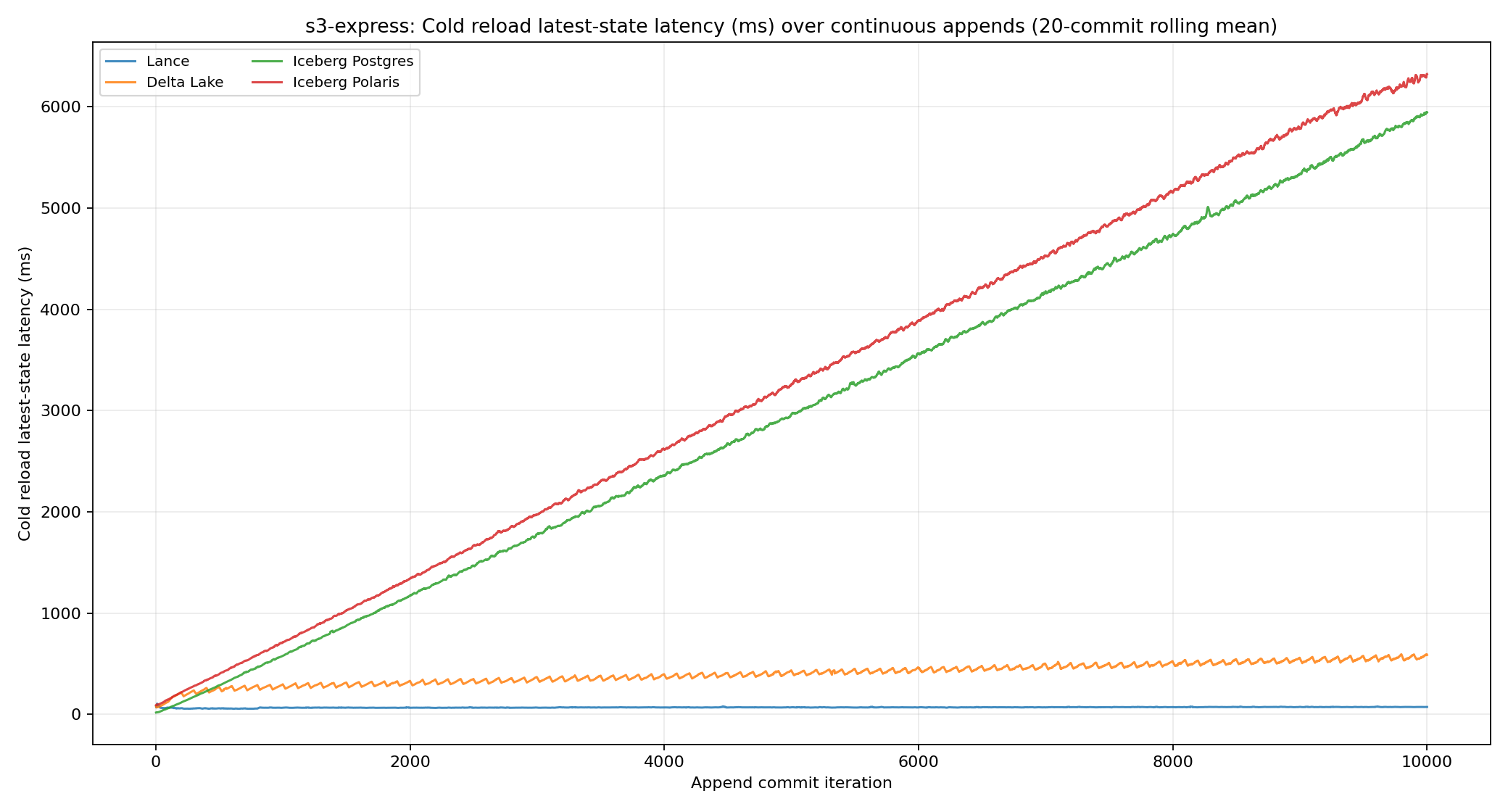
Metadata load latency
Metadata load latency again separated the designs. Lance ended around 73 ms. Delta Lake ended around 559 ms. Iceberg Postgres and Iceberg Polaris ended around 5.8 seconds and 6.2 seconds.
Why Lance is the best performer
Lance load latency stays low on S3 Express because the load path is mostly latest-version discovery plus decoding a compact manifest. Faster object storage helps everyone, but it helps the design with fewer metadata bytes and fewer dependent metadata reads the most.
Delta Lake still has to reconstruct active file state from a checkpoint and log tail. Iceberg can reach the latest snapshot through the catalog, but then it has to read a much larger metadata tree. Lance keeps the active latest-state metadata small: the final S3 Express active metadata set was 0.78 MiB for Lance, 2.17 MiB for Delta Lake, and roughly 44 MiB for both Iceberg variants.
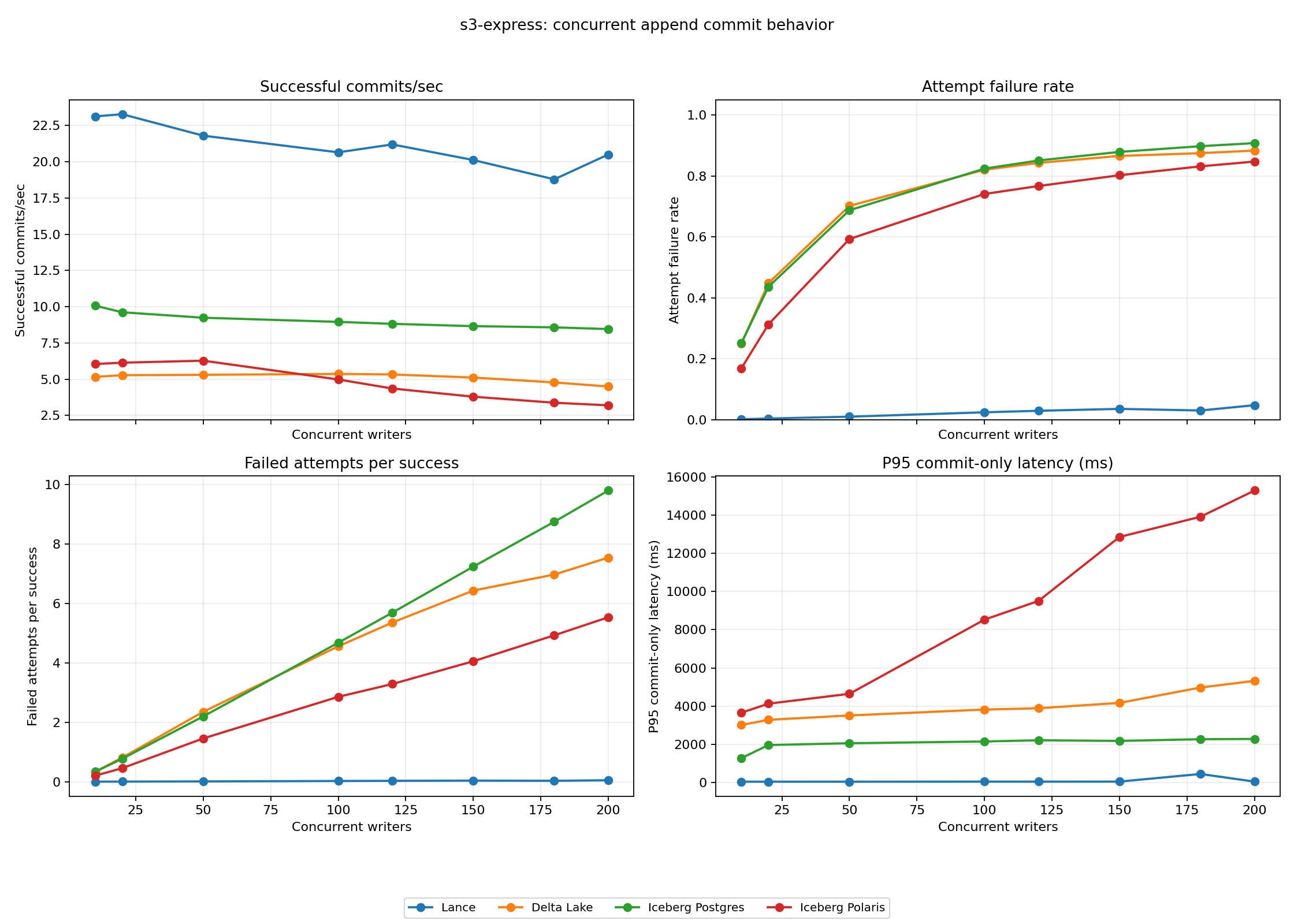
Concurrent commit throughput
Concurrent commit throughput showed the same stability difference. At 200 writers on S3 Express, Lance sustained 20.5 successful commits/sec with a 4.8% failed-attempt rate. Delta Lake sustained 4.5 successful commits/sec with an 88% failed-attempt rate. Iceberg Postgres sustained 8.5 successful commits/sec with a 91% failed-attempt rate. Iceberg Polaris sustained 3.2 successful commits/sec with an 85% failed-attempt rate.
Why Lance is the best performer
The pattern is mostly the same as standard S3: Lance wins because it combines small metadata, fast load, fast full commit, and low retry waste. The main difference is Delta Lake’s much worse S3 Express result, which follows from the unordered _delta_log/ listing behavior discussed above.
S3 Express raises the ceiling, so the format-level retry behavior becomes even more visible. Lance had the fastest metadata commit path, the fastest metadata load path and the smallest active metadata footprint. More importantly, it converted those advantages into successful throughput without creating a large retry storm.
At 200 writers, Lance reached 20.5 successful commits/sec with only a 4.8% failed-attempt rate. The other formats spent most attempts on conflicts: Delta Lake failed 88.3% of attempts, Iceberg Postgres failed 90.7% and Iceberg Polaris failed 84.7%. On fast object storage, Lance’s lower retry rate is a throughput feature: it leaves more of the storage budget for successful commits instead of failed attempts.
Afterthoughts
Overall, I am extremely happy with these results. They represent years of optimization from the Lance open source community to get the format to this point on object storage. Here are a few personal thoughts after running the benchmarks and walking through the results.
How can a flat list of files scale?
One common question is: this works with 10,000 files, but how can a flat manifest of files scale to petabyte- or exabyte-scale datasets?This question often comes from people who have read the Iceberg format spec and understand why its 2-level manifest tree was designed for planning over very large file counts.
In this benchmark, after 10,000 appends, the active latest-state metadata was approximately:
- Lance: 0.78 MiB, or about 82 bytes per active fragment.
- Delta Lake: 2.16 MiB, or about 226 bytes per active data file.
- Iceberg Postgres: 42.84 MiB, or about 4.5 KiB per active data file.
No table format suggets that millions of tiny files a good idea. If a user writes a new file for every tiny event and never compacts, any system would suffer. But with reasonable fragment sizing, the per-fragment metadata slope matters a lot. Lance’s default sizing is about 1 million rows per fragment, so a trillion-row dataset is about 1 million fragments. Under the observed slope of roughly 82 bytes per fragment, the active Lance manifest would be about 82 MB and can still be processed efficiently.
By contrast, using Iceberg’s observed slope of roughly 4.5 KiB per active data file, the same 1 million-file scale would produce about 4.3 GiB of active metadata. That is the irony of Iceberg’s metadata design: the 2-level manifest tree is meant to make very large tables plannable, but it can also create a large metadata problem of its own. Luckily, the Iceberg community is already actively working on this problem with the single-file commit feature in Iceberg V4, which we discuss next.
How far can single-file commit improve Iceberg?
The single-file commit proposal is the right direction for Iceberg. It attacks the metadata amplification that shows up in this benchmark by replacing the manifest list with a Root Manifest and making small operations closer to writing one new metadata object.
But it does not magically turn Iceberg into Lance or Delta Lake. Iceberg still keeps metadata JSON above the new Root Manifest, that JSON metadata file still grows linearly with the number of commits, and the format still requires a catalog commit as the atomic publish point. The expected performance shape is better than current Iceberg, especially for small writes, but still structurally heavier than Delta Lake’s log/checkpoint path and Lance’s compact manifest path.
There is also a practical adoption question. This is a major metadata design shift for a widely deployed format with many engines, catalogs, and maintenance tools. How long it will take for the ecosystem to standardize, implement, deploy, and make this path common in production remains to be seen.
In other words, Iceberg single-file commit is useful and important progress. It narrows one of Iceberg’s biggest write-path gaps, but it is not a reason to expect Iceberg to leapfrog formats that were already optimized around this metadata shape.
What about catalog-based commit acceleration?
Both Iceberg and Delta Lake are increasingly leaning on catalog integrations as the place to hide more commit intelligence. This is also a key part of unifying Iceberg and Delta Lake on top of the single file commit project. There are real opportunities there.
For Iceberg, server-side commits can potentially improve conflict handling because the service has more context than a stateless client retry loop. A catalog could also choose to return trimmed metadata, avoid sending unnecessary historical versions to readers, or maintain auxiliary state that makes latest-snapshot loading cheaper.
Delta Lake is moving in the same direction with catalog-managed tables. Delta’s protocol makes the tradeoff explicit: when catalogManaged is enabled, the catalog becomes the source of truth for whether commits succeed, filesystem-based access is not supported, writers must commit through the catalog, and readers must contact the catalog for ratified commit information. The protocol also says catalogs may return table-level metadata so clients can skip some log replay and filesystem listing. That can be a powerful optimization.
But it also changes the nature of the system. A catalog-managed Delta table is no longer the same storage-only Delta table. It now depends on a catalog hook for discovery, reads and writes. If the catalog optimization pays for that hook, performance can improve. If it does not, the extra catalog path adds latency and operational dependency. This is a natural evolution in a world where Databricks is pushing Unity Catalog, but it also means more of the performance story can move behind a commercial or deployment-specific control plane. The exact effect becomes harder to measure from the open storage format alone.
I have to confess this was also part of my own thinking when I originally proposed server-side planning and commit for Iceberg. One goal was to put Redshift-based optimization behind the Iceberg REST Catalog as a part of the SageMaker lakehouse, using the open table format as the interface while placing heavy commercial compute behind it to drive compute usage. There is nothing wrong with that model, and it is now used for very similar purposes by multiple vendors. But it ultimately makes the system less open, harder to measure, and more dependent on heavier infrastructure.
Lance takes a stronger stance here. Catalog integration is important, and we will continue improving catalog integrations and adding catalog-side acceleration. But the storage-only format must remain compatible and fast on storage. That is a core feature request from ML and AI engineers from day one, and it is one of the reasons more and more frontier labs and agentic frameworks are choosing LanceDB: a table can be useful, durable and performant on any storage system without first requiring a separate catalog service and heavy commercial product installation.
Why this is important for Lance
For agents
The key pattern with agents is that they make data creation extremely cheap. An agent can create and open thousands of tables, write memories, traces, tool results, embeddings, artifacts, and checkpoints, and then come back to any one of them at any time. The access pattern is not a clean nightly batch job. It is random, incremental, and hard to predict.
That means the table format has to be resilient to random operations thrown at it: many small tables, many small commits, cold opens, occasional bursts, and reads or writes against old tables that have not been touched for a while. Lance is becoming the default memory layer for more agent systems like OpenClaw exactly because it stays storage-native, compact, and predictable under those patterns without requiring a separate maintenance service to keep the metadata healthy.
For infrastructure
Once a table format has a fast, storage-only, atomic metadata protocol, it becomes a building block. A Lance table can back catalogs, queues, event logs, job coordinators, and other metadata-heavy systems that need durable state on object storage without deploying another database.
We already use Lance tables widely for operational components inside LanceDB. The community is also building projects such as lance-graph that take advantage of Lance as an efficient storage-native building block rather than only as a user-facing data table.
This is the deeper point of the benchmark. Lance is not just faster because one code path is optimized. It is faster because the format aligns with the object storage performance model:
- publish compact current state;
- avoid external catalog dependencies;
- avoid unbounded log replay;
- race discovery paths and take the fastest valid result;
- keep metadata binary and small.
Delta Lake and Iceberg are excellent systems with different design centers. Delta is a log. Iceberg is a cataloged metadata tree. Lance is a compact storage-native manifest with transaction details tied directly to the published manifest.
For object storage, that turns out to be the right shape.
Conclusions
I started this post with a simple question: after years of pushing Lance toward the physical transactional limits of object storage, have we actually perfected everything we can do with the commit primitive object storage gives us today?
My answer after this benchmark is yes, at least for this generation of storage-only table formats. Lance is not just faster in one chart. It is consistently smaller, faster to commit, faster to load, more stable under concurrency, and more naturally aligned with object storage semantics.
That gives me a lot of confidence about the foundation we have built. It also means I can finally move on to the more exciting question: “If Lance is already near the limit of what object storage commit semantics can offer today, how do we get even better?”
Stay tuned. That is the next chapter. 🚀


