

As Continue offers user-controlled IDE extensions, most of the codebase is written in TypeScript, and the data is stored locally in the ~/.continue folder. The tooling choices are made such that there are no separate processes required to handle database operations. Continue’s codebase retrieval features are powered by LanceDB, as it is the only vector database with an embedded TypeScript library capable of fast lookup times while being stored on disk, while also supporting SQL-like filtering.
Continue seamlessly integrated LanceDB to transform codebase search, deploying a production-ready solution in under a day. This rapid implementation not only accelerated development but also aligned with Continue’s foundational principles: a local-first architecture that prioritizes developer privacy and offline capability, ensuring sensitive code never leaves the user’s machine.
Introduction
Agent Mode in Continue demonstrates AI-powered code assistance that understands context and semantics beyond traditional keyword matching.
Continue reimagines how developers harness AI, transforming it from a rigid tool into an extension of the workflow. With open-source extensions for VS Code and JetBrains, Continue empowers developers to build, customize, and deploy AI coding assistants tailored to unique team patterns, preferences, and codebases. Models, prompts, rules, and documentation can all be integrated into one unified toolkit within the IDE, and all under your control.
While Continue operates locally by default, storing data securely in the ~/.continue directory, it is built to scale beyond individual setups into server or cloud environments for teams. Organizations can extend its core Retrieval Augmented Generation (RAG) system through a flexible context provider API, integrating proprietary databases, internal documentation, or legacy codebases to create tailored AI assistants.
{{text-idea1}}
Continue is not just another AI tool. It is a developer-defined ecosystem where teams shape how AI accelerates their work. Build smarter, ship faster, and focus on what matters: creating exceptional code.
The Challenge
Developers often work with vast codebases, intricate libraries, and sprawling documentation. Traditional keyword-based search tools struggle to keep pace, failing to surface semantically relevant code snippets, identify nuanced patterns, or retrieve contextually aligned resources.
Core Requirements
To solve this, Continue required a solution that could:
- Understand Code Semantics: Move beyond superficial text matching to analyze the intent and logic behind code, enabling accurate retrieval of functionally similar patterns.
- Accelerate Developer Workflow: Deliver instant, context-aware recommendations as developers type, eliminating disruptive latency during critical thinking phases.
- Scale Seamlessly: Support massive codebases and diverse programming languages while maintaining consistent performance, even under heavy workloads.
Technical Constraints
To integrate this capability directly into its open-source VS Code and JetBrains extensions, Continue needed a vector database that prioritized privacy, simplicity, and tight integration with developer environments. The solution had to meet stringent criteria.
{{text-idea2}}
Continue’s requirements for a vector database were unequivocal. It needed an embedded TypeScript library to ensure seamless integration, lightning-fast lookup times even with on-disk storage, and robust SQL-like filtering capabilities to enable precise, context-aware queries. These features were non-negotiable for delivering a performant, developer-centric experience.
The Solution
There are a number of available vector databases which are able to performantly handle large codebases. LanceDB stood out as the only vector database offering an embedded TypeScript library with local disk storage, enabling Continue to deliver a frictionless, self-contained experience. Its performance-optimized design ensured sub-millisecond lookup times, even with large codebases, while robust SQL-like filtering allowed developers to refine searches with surgical precision.
LanceDB is a good choice for this because it can run in-memory with libraries for both Python and Node.js. This means that in the beginning our developers can focus on writing code rather than setting up infrastructure.
— Nate Sesti, Cofounder & CTO at Continue
By storing vectors directly on disk in Lance format, LanceDB also future-proofed Continue’s architecture, ensuring effortless scalability from local experimentation to enterprise-grade deployments.
Implementation Architecture
Here is how Continue leverages LanceDB to power its AI-driven code understanding.
Step 1: Code Semantic Embedding
Continue converts code snippets, functions, and documentation into high-dimensional vectors using embedding models (like Voyage AI’s code embedding model). This captures the meaning of code—not just keywords—enabling the AI to recognize similarities even when syntax differs (e.g., identifying equivalent logic in Python and JavaScript).
Step 2: Local Codebase Ingestion
The system crawls the local repository, chunking code into manageable segments such as 10-line blocks. For a 10 million line codebase, this creates roughly 1 million vectors. LanceDB’s in-memory architecture keeps this process fast and resource-efficient, while its disk-based storage keeps data persistent and secure.
Step 3: Indexing for Speed & Precision
Continue calls LanceDB APIs to build vector + scalar indexes. This combination allows Continue to retrieve results in milliseconds, even with massive datasets.
Step 4: Context-Aware Developer Queries
When a developer searches (“How do we handle API retries?”) or requests AI assistance, Continue uses LanceDB to:
- Perform a vector search to find semantically related code.
- Apply SQL-like filters (language, project, tags) to refine results.
- Return contextually relevant suggestions directly in the IDE.
Step 5: Seamless Codebase Updates
As developers work across branches or update code, LanceDB’s optimizations prevent redundant work:
- No full reindexing: Small changes (e.g., two similar branches) only update affected vectors.
- Embedding flexibility: Swap models (like trying OpenAI vs. custom embeddings) without rebuilding the entire database.
Results & Impact
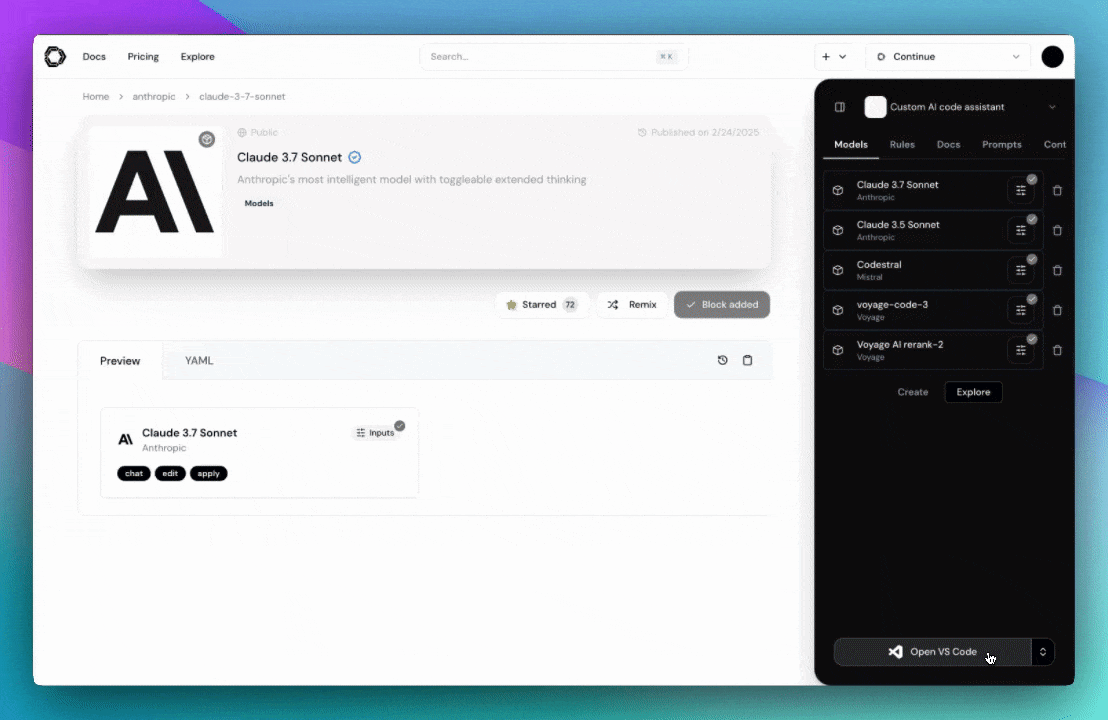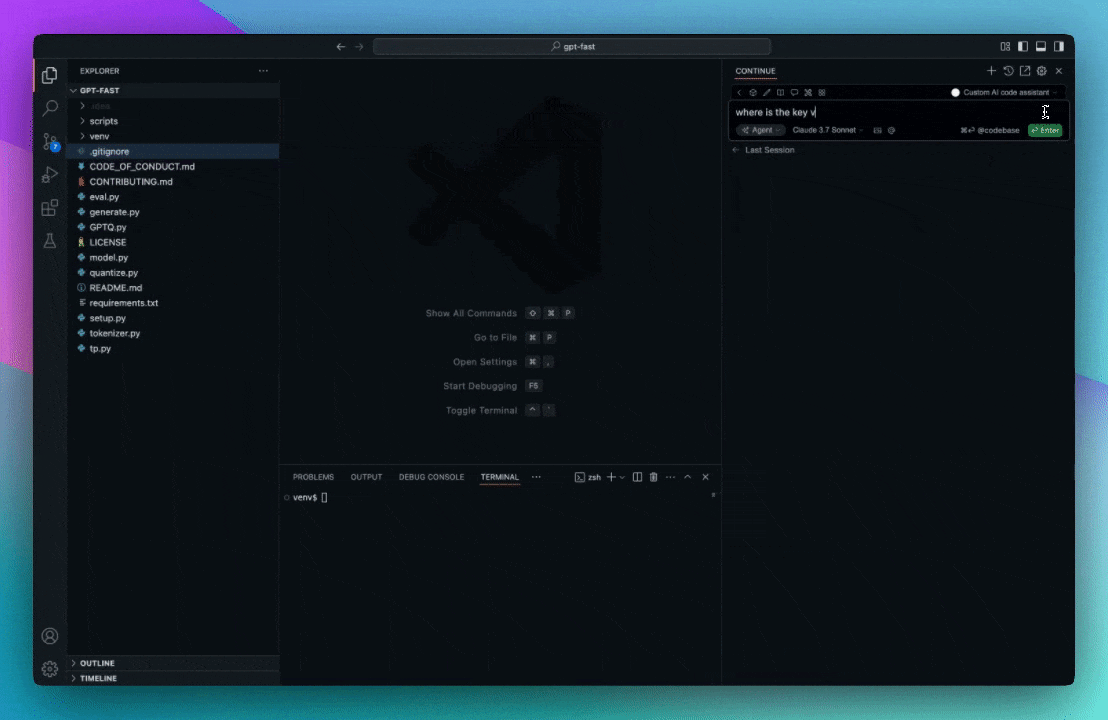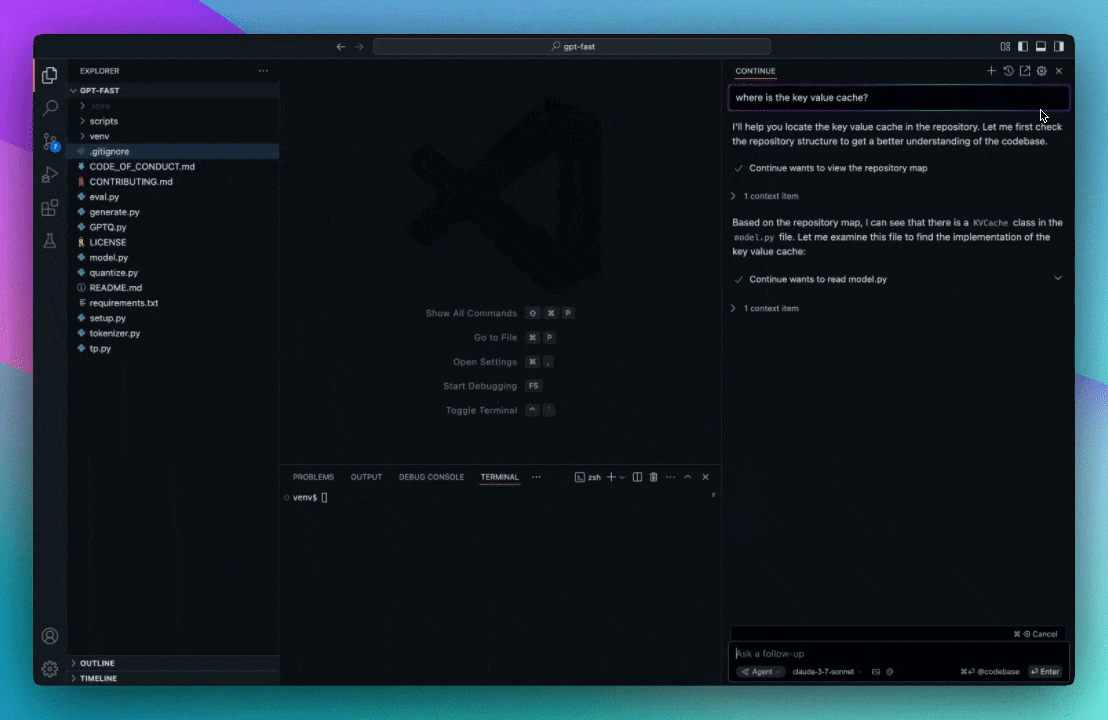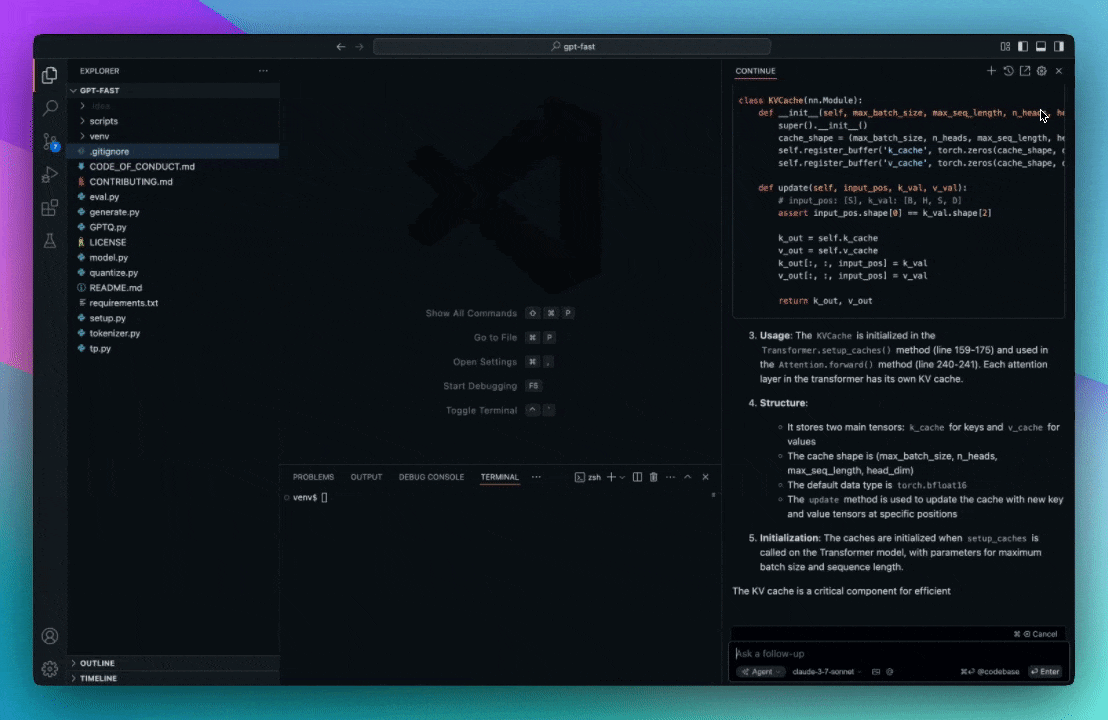
Continue’s IDE integration showcasing context-aware code suggestions powered by LanceDB’s semantic search capabilities.

By integrating LanceDB, Continue has successfully transformed its coding assistance capabilities, providing developers with fast, context-aware suggestions that go beyond simple keyword matching.
Performance Metrics
- Faster Development: Auto-completion suggestions improved by 40% in relevance, reducing time spent debugging with context-aware error resolution.
- Scalability: Handled 1M+ vectors with <10ms latency per query, even on modest hardware - no excessive memory needed.
- User Personalization: Developers working on ML projects saw tailored suggestions for PyTorch/TensorFlow snippets.
“Thanks for all the work that you do! When I found LanceDB it was exactly what we needed, and has played its role perfectly since then : )”
— Nate Sesti, Cofounder & CTO @Continue
The Future of AI-Native Development
As Continue reimagines the future of developer tools, it is pioneering a world where AI assistants transcend code to become holistic collaborators. Continue is laser-focused on empowering developers to interact with any resource - code, images, videos, PDFs, or design specs - as intuitively as they write functions today, all powered by LanceDB’s native multimodal support and advanced multivector search.
As enterprises adopt Continue to democratize AI-powered coding across global engineering teams, LanceDB’s scalable cloud infrastructure and enterprise-grade security will anchor mission-critical deployments - enforcing compliance, accelerating cross-team collaboration, and future-proofing innovation as organizations grow.
The future belongs to teams that treat AI as a living extension of their collective expertise. With LanceDB as our backbone, Continue will keep turning this vision into reality - one line of code, one breakthrough, and one enterprise at a time.
Learn More
Continue Resources:
- Website - Official Continue homepage
- Documentation - Complete setup and usage guides
- GitHub Repository - Open-source codebase
LanceDB Resources:
- Website - LanceDB platform overview
- Documentation - Technical documentation and API references
- GitHub Repository - Open-source vector database
- Discord Community - Join our developer community
- Example Recipes - Get started with LanceDB examples



