

World models are learned predictive models of how an environment evolves under actions. These are central to agents that can plan, reason, and generalize beyond their training data. Recent work (LeWorldModel, DINO-WM, V-JEPA2, PLDM, TD-MPC2) keeps pushing the modeling story forward, but the surrounding research infrastructure is fragmented: every paper ships a one-off codebase, every implementation reinvents the same data pipeline and the same handful of planning solvers, and there's no shared evaluation surface for fair comparisons.
Stable-Worldmodel is the open-source platform built to fix that. One package, one set of abstractions for data collection, training, and evaluation, clean reference implementations of every modern baseline (LeWM, DINO-WM, PLDM, TD-MPC2, GCBC and friends), planning solvers (CEM, MPPI, iCEM, gradient-based), and a controllable-perturbations evaluation suite that lets you measure zero-shot generalization with a single number.
Read the paper on arXiv here.
Underneath all of it sits a LanceDB data layer. LanceDB is a multimodal lakehouse built on the open-source Lance columnar format, optimized for modern multimodal AI access patterns.
The data layer
This high-performance default data layer built on top of LanceDB has several advantages.
1. Dataloader throughput is high enough to keep a modern GPU saturated. For example, on a single H200 we see roughly 40k steps/hour with Lance when training LeWM model, versus ~20k steps/hour against the same dataset in HDF5, and even less with popular video-based dataloaders that decode frames from videos on-the-fly.
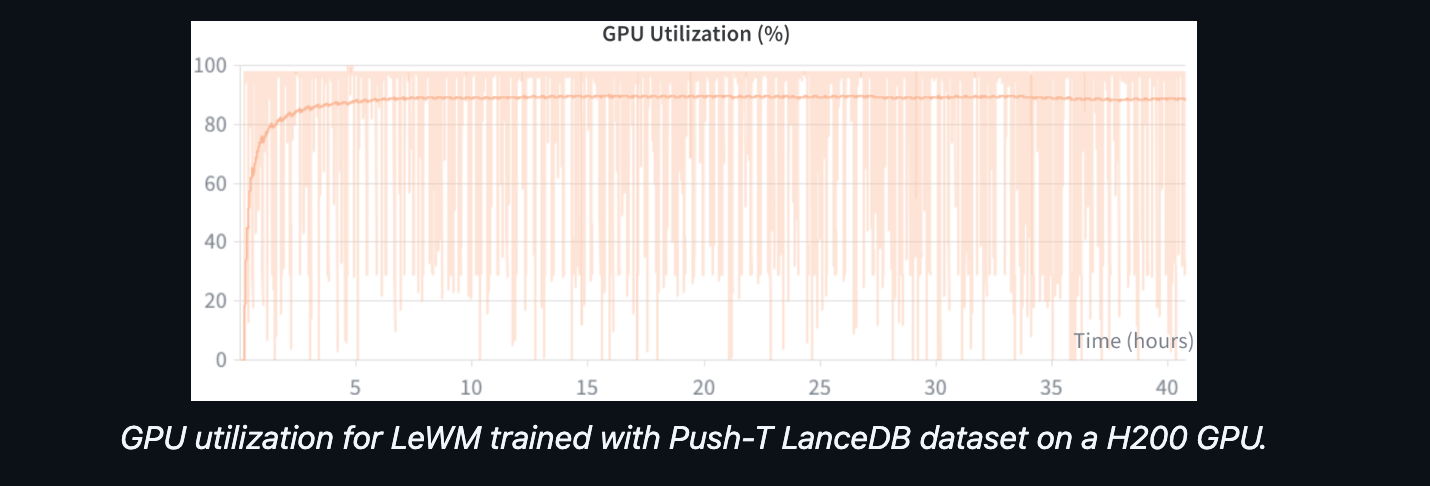
2. Reading LanceDB datasets directly from a remote bucket is performant, which makes training directly from object storage a viable workflow rather than paying the significant cost to sync to local disk upfront. You effectively keep your GPUs fed, while training directly off of object storage.
3. Index support and zero-copy data evolution: You can have search indexes like vector, FTS and hybrid search on the same training dataset to explore and curate your training data more easily, without any additional cost or performance loss. This is because LanceDB supports zero-copy data evolution, which means adding new features is essentially free.
A quick tour
Stable-Worldmodel builds on three abstractions: a World (vectorized Gymnasium environments + controllable perturbations), a Policy (anything with get_actions), and a Solver (the planning algorithm an MPC policy calls into). The library essentially composes these three abstractions:
1. Collect: dump trajectories into a Lance table
world = swm.World("swm/PushT-v1", num_envs=8, max_episode_steps=1000)
world.set_policy(your_expert_policy)
world.collect(dataset_path="pusht.lance", episodes=5000, seed=42)
2. Train: same loader path works for local, S3, GCS, or HF Buckets URIs
dataset = swm.data.load_dataset("pusht.lance", num_steps=16)
trainer.fit(world_model, DataLoader(dataset, batch_size=256, num_workers=8))
3. Evaluate under controlled perturbations
planner = swm.solver.CEMSolver(world_model)
world.set_policy(swm.policy.MPCPolicy(planner))
metrics = world.evaluate(
episodes=100, video="videos/",
options={"variation": ["agent.size", "background.color"]}
)
print(metrics["success_rate"])None of these blocks cares whether pusht.lance is a local directory, an s3:// URI, or a Hugging Face Hub URI like hf://buckets/<org>/<bucket>/pusht.lance.
Training LeWorldModel using stable-worldmodel
To ground the data-layer numbers in a real model, the canonical baseline in the SWM zoo is LeWorldModel (LeWM).
LeWM is a latent dynamics model in the JEPA family with a deliberate twist: it trains end-to-end from raw pixels with only two loss terms, rather than relying on a frozen DINOv2 encoder the way DINO-WM does. The forward pass looks like the following:
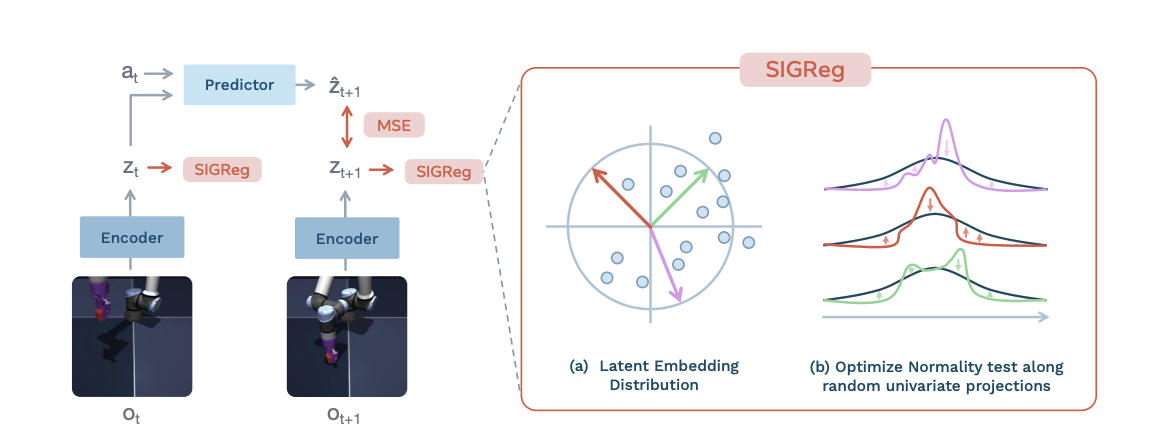
There are three design points worth calling out:
- End-to-end from pixels. Most JEPA-style world models bolt onto a frozen pretrained encoder. LeWM trains the encoder, action embedder, and predictor jointly. This is what gives the 192-dim embedding its expressiveness. roughly 200× more compact than DINO's patch tokens and what makes planning fast: the encoder isn't a 1B-parameter foundation model, it's a small ViT (Vision Transformer) sized for the task.
- SIGReg as collapse prevention. Joint-embedding architectures classically collapse to a constant unless you stop them with EMA targets, stop-gradients, predictor heads on the target side, or some combination. LeWM uses SIGReg instead: a regularizer that softly pushes the latent embedding distribution toward an isotropic Gaussian. One scalar weight λ to tune instead of a half-dozen pretraining-recipe knobs.
- Two losses, one optimizer. The full training loss is
pred_loss + λ · sigreg_loss, both differentiable end-to-end with no auxiliary supervision. Training runs to convergence on a single H200 in hours, not days.
The result is SOTA-competitive numbers on Push-T (94% success rate) and OGBench-Cube (72%) with roughly 50× less planning latency than DINO-WM.
Training from object storage
LanceDB can read from different kinds of storage services in the unified API powered by Apache OpenDAL, so swm's loader is URI-agnostic: s3://, gs://, az://, a local path, or the newly launched Buckets (Hugging Face's S3-alike object storage service) using the hf://buckets///.lance URI.
Storage Buckets are a recent addition to the Hugging Face Hub: they're mutable, S3-like object stores that you can explore in the browser, script from Python, or manage with the Hugging Face CLI. Unlike Models and Datasets repositories, they aren't version-controlled.
Why does this matter for Lance?
As modern AI data infrastructure tools, Lance and HF Buckets share a common design philosophy: break data into small, independently-accessible chunks. Where a traditional object store sees monolithic files, both Lance and Buckets (built on top of Xet) see collections of small pieces. That alignment means you benefit from deduplication at no extra cost.
The pre-warming feature is another win for large-scale reads. When your Lance tables span terabytes of data, reducing time-to-first-byte and saturating bandwidth across your most active regions (GCP US East, GCP EU West, AWS EU West) directly translates to faster training job completion. And on top of all that, if you're already using Hugging Face's tooling, there's zero new surface area. Same CLI, same Python client, same fsspec or OpenDAL abstraction.
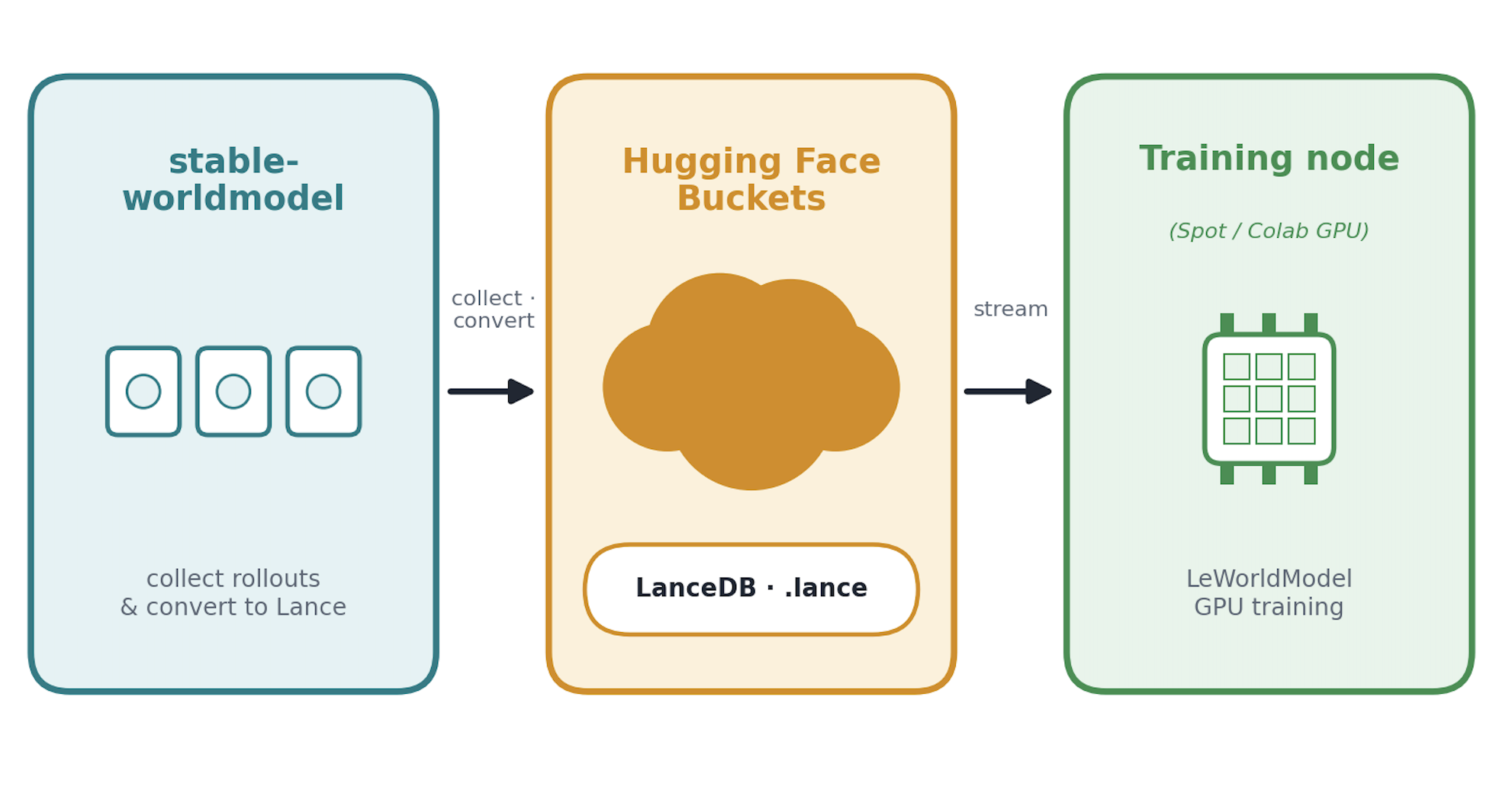
The training command takes any of those URIs interchangeably:
export HF_TOKEN=...
python scripts/train/lewm.py data=tworoom data.dataset.name=hf://buckets/your-org/your-bucket/tworoom.lanceThis allows faster iteration and experimentation:
- Spot instances stop being painful: there's nothing to sync, so an interruption costs minutes of progress, not a multi-GB resync.
- Colab and other hosted notebooks become reasonable training targets, since the large local download is no longer the gate.
- Multi-region experiments are a config change.
- For HF-hosted datasets specifically, the dataset, baselines, checkpoints, and demo Spaces can live under one organization.
Convert to Lance in one command
If your dataset is in a different format like HDF5 or LeRobot's Parquet + video layout, porting to LanceDB is just a simple 1-line command. swm ships a converter that streams episodes one at a time so memory stays bounded:
1. Convert using the stable-worldmodel CLI:
swm convert --source tworoom.h5 --dest tworoom.lance
2. Push to HF Buckets (or any other object store):
huggingface-cli buckets upload your-org/your-bucket tworoom.lance
3. Train:
python scripts/train/lewm.py data.dataset.name=hf://buckets/your-org/your-bucket/tworoom.lance
Conclusions
stable-worldmodel is an open-source platform for reproducible research and evaluation of world models, providing modular tools for data management, planning, and standardized benchmarks with customizable visual and physical properties. Our experiments show that current world models still struggle with robust zero-shot generalization under even mild distribution shifts, and swm aims to make future progress more measurable, scalable, and reproducible.
Try it now
pip install stable-worldmodel
Try the 2 min Colab walkthrough
Additional Resources
- GitHub: galilai-group/stable-worldmodel
- Paper: https://arxiv.org/abs/2605.21800
- LeWorldModel: le-wm.github.io
Acknowledgements
We would like to thank our collaborators on this work:
- The authors of stable-worldmodel paper: Lucas Maes, Quentin Le Lidec, Luiz Facury, Nassim Massaudi, Ayush Chaurasia, Francesco Capuano, Richard Gao, Taj Gillin, Dan Haramati, Damien Scieur, Yann LeCun, Randall Balestriero
- Quentin Lhoest from Hugging Face for lending expertise on HF buckets and helping integrate with it.






