

Imagine a product catalog table with ordinary columns for id, category, label, and embedding, plus one column for the product image. On Monday the pipeline ingests images. On Tuesday a classifier fixes a label. Consider this simple SQL update:
UPDATE products SET label = 'discontinued' WHERE id = 42;Nothing in that statement asks to decode the existing image, resize it, classify it, or send it across the network. But if the image is modeled as an inline BINARY column in Spark, as it often is in Parquet- or Iceberg-backed tables, Spark still has only one abstraction for the value: bytes inside a row. When row-level SQL rewrites rows, the blob column has to survive the plan, and the default way for it to survive is to move the payload with the row.
This is the mismatch we focus on in this post. Multimodal tables are usually mostly metadata with a few very large assets. Spark is good at moving rows. Large assets want a different contract: keep a small reference in the query plan, and materialize bytes only at a boundary that actually needs bytes.
The tradeoff Spark usually forces
Spark users work around this today in one of two ways.
They can store the asset inline as BINARY. That keeps SQL simple, but every job that touches the row risks carrying image, audio, document, or video bytes through scans, joins, shuffles, caches, and row-level rewrites.
Or they can store a path column such as s3://bucket/images/123.jpg. That is cheap to shuffle, but now the table no longer owns the asset. Every downstream job has to know how to fetch it, which credentials to use, which version it points at, and whether a MERGE that updates labels also preserved the right image.
The goal of the new Lance Blob V2 support in Lance Spark is to remove that per-application tradeoff. Users should be able to model an image as a column, write SQL against that column, and still avoid moving bytes through Spark stages when the query only needs to preserve the asset.
What Blob V2 gives Spark
Blob V2 is Lance's storage abstraction for large binary data. It is still one logical column in the table, but each value can use the physical layout that fits that value: inline for small payloads, packed with other blobs, in dedicated blob files, or externally via URIs.
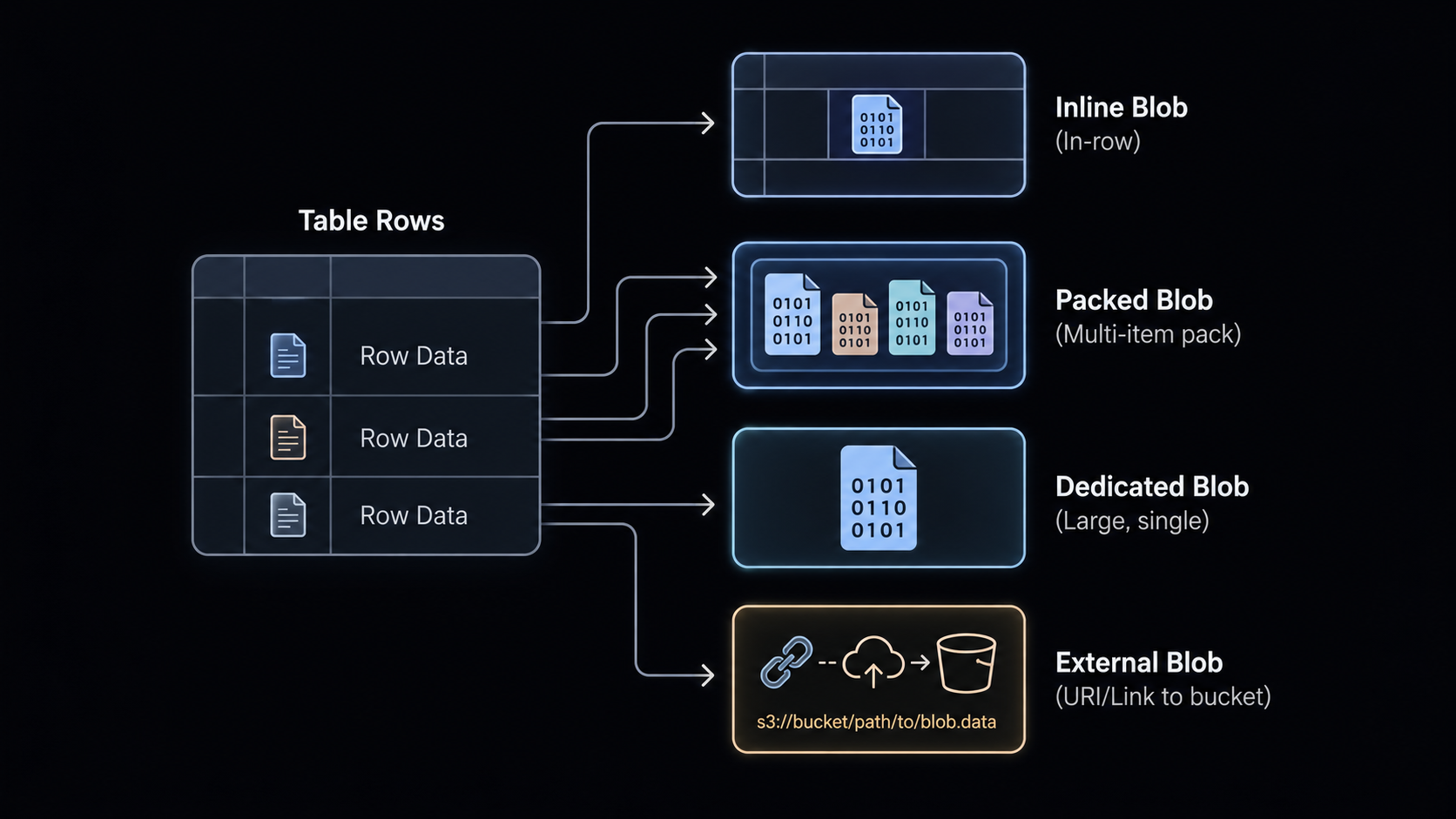
With this design, a mixed table with small thumbnails, medium crops, and large clips can use different layouts row by row without the user needing to split schemas or choose a layout for each row.
When Lance Spark scans a Blob V2 column, it does not expose the payload as byte[]. It exposes a descriptor:
struct<kind:short, position:long, size:long, blob_id:long, blob_uri:string>That descriptor is enough to answer questions like "what is the blob size?" and enough for the connector to find the bytes later. A query like this does not fetch the image bytes:
SELECT id, image.size, image.kind
FROM lance.db.products
WHERE category = 'shoes';On write, Spark users can still provide BINARY. A table created with Blob V2 properties accepts binary input, and the connector writes it as a Blob V2 column:
CREATE TABLE lance.db.products (
id INT NOT NULL,
category STRING,
label STRING,
image BINARY
) USING lance
TBLPROPERTIES (
'image.lance.encoding' = 'blob',
'file_format_version' = '2.2'
);
INSERT INTO lance.db.products VALUES
(1, 'shoes', 'active', X'89504E47');The important part is that reads and writes do not have to use the same physical representation inside Spark. Reads can stay descriptors. Writes can accept bytes. Lance Core decides where the bytes live and keeps that decision inside the dataset's versioned storage model.
That points at the deeper Spark abstraction gap. A large asset column wants multiple execution representations under one logical schema: metadata for reads, bytes for direct writes, and references for Lance-to-Lance movement. The value does not always need to become bytes inside Spark just because a row is being rewritten. If the writer has enough source context, materialization can be pushed all the way down to the write path.
The earlier tradeoff becomes easier to see once Blob V2 is part of Lance Spark:
Reference passthrough, not byte passthrough
The Spark connector now uses reference passthrough for safe Lance-to-Lance writes. In the implementation this is the copy-through path: the optimizer replaces a direct Blob V2 column assignment with a small copy token, and the writer later resolves that token to real bytes.
The token contains the information the writer needs: the source dataset context, the source row address, and the blob column. Spark can project, join, filter, and shuffle that token like a small value. The Lance writer materializes the bytes only on the write path.
The Spark connector does not create a separate blob system; it preserves enough source context for Lance Core to apply Blob V2's normal layout, materialization, versioning, and write rules.
Spark keeps moving small values; Lance owns the asset materialization.
A row through a MERGE plan
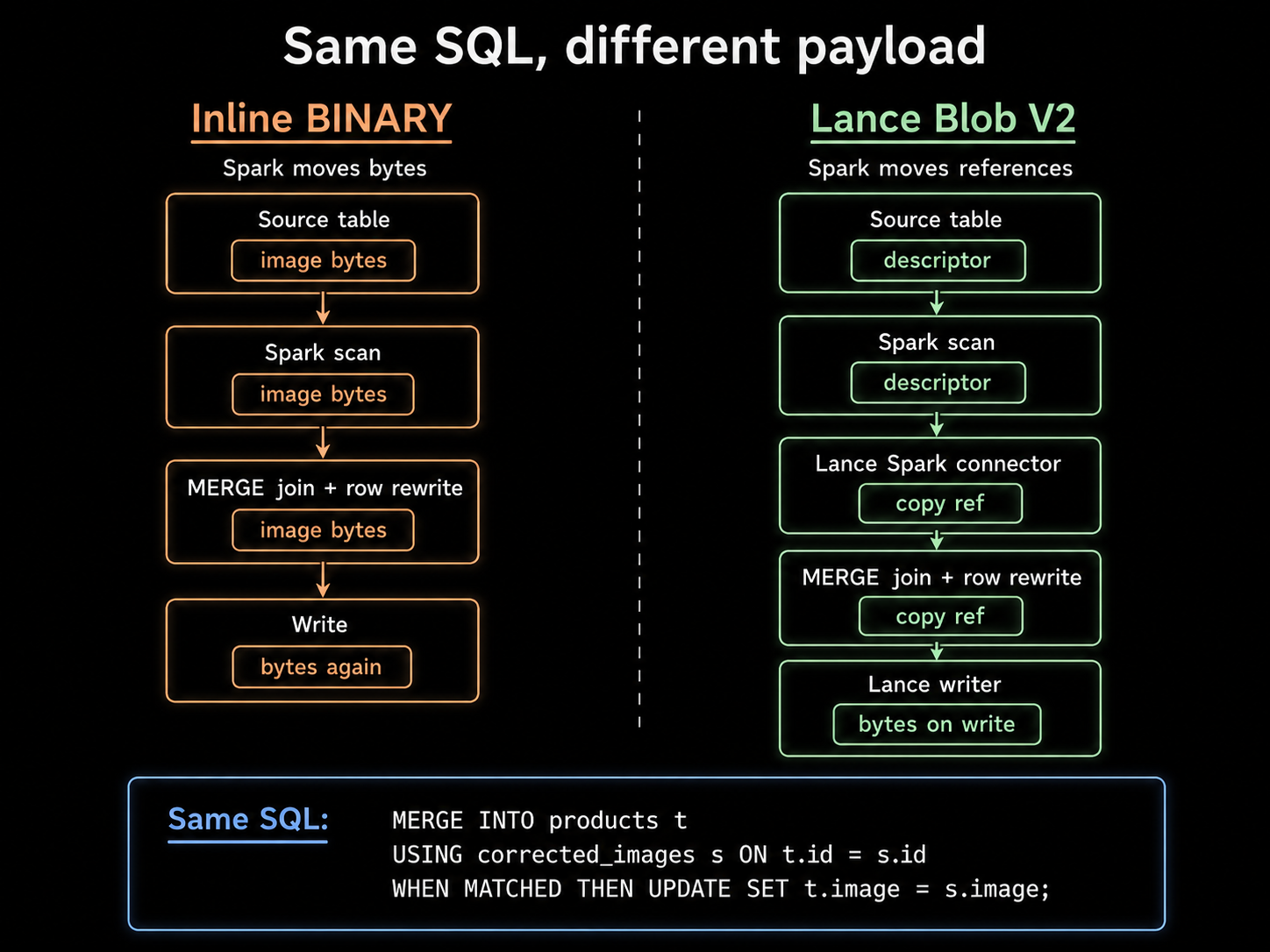
The MERGE stays just as simple; all that changes is the payload Spark carries.
SQL that benefits
INSERT and CTAS
The simplest case is copying a Blob V2 column from one Lance table to another:
INSERT INTO lance.db.products_archive
SELECT id, category, label, image
FROM lance.db.products
WHERE category = 'seasonal';With inline BINARY, image is the bytes. With Blob V2 reference passthrough, image is a reference until the archive table is written. The job still creates real blob values in the target table; Spark just does not have to shuffle the payloads.
Joins that keep blobs as references
If product metadata comes from one table and images from another, Spark can join on ordinary columns while the image column remains a reference:
INSERT INTO lance.db.training_examples
SELECT p.id, p.category, i.image
FROM lance.db.product_metadata p
JOIN lance.db.product_images i
ON p.id = i.id
WHERE p.split = 'train';One-to-many joins work too. If one image fans out to several labels or crops, each output row carries its own reference and the writer copies the blob into the rows it writes.
MERGE and UPDATE
Row-level DML is the more important case because it is where inline bytes hurt most. Updating metadata should not require Spark to read and shuffle unchanged images:
MERGE INTO lance.db.products t
USING lance.db.label_fixes s
ON t.id = s.id
WHEN MATCHED THEN UPDATE SET t.label = s.new_label;
UPDATE lance.db.products
SET label = 'archived'
WHERE category = 'seasonal';For these statements, Spark still rewrites rows under the hood. The connector has to carry the untouched target blob forward so the rewritten row is complete. Blob V2 reference passthrough lets the connector preserve that target image by reference and materialize it during the write.
When the SQL really does replace a blob from a source table, the same mechanism copies from the source:
MERGE INTO lance.db.products t
USING lance.db.corrected_images s
ON t.id = s.id
WHEN MATCHED THEN UPDATE SET t.image = s.image
WHEN NOT MATCHED THEN INSERT (id, category, label, image)
VALUES (s.id, s.category, 'new', s.image);This is the core behavior behind the new Spark work: INSERT ... SELECT, CTAS, replace-table-as-select, and Spark 3.5+ MERGE and UPDATE can preserve Blob V2 columns without turning descriptors into user-managed path columns or shuffling raw payloads.
Built into Lance Spark
There is no new copy API or per-job layout decision for users. If SQL preserves an existing Blob V2 value, Lance Spark carries source context through the plan and Lance Core materializes bytes on the write path.
That is what makes INSERT ... SELECT, CTAS, joins, MERGE, and UPDATE feel like normal Spark SQL: the connector keeps preserved blob values as references.
If a query turns a descriptor into a new value, Spark keeps descriptor semantics. The detailed support matrix belongs in the Spark Blob V2 docs.
Why this matters
There are two wins. The first is performance: metadata-only and Lance-to-Lance jobs can move small references instead of dragging large binary payloads through scans, shuffles, and row rewrites. The second is ease of use: users do not have to pick layouts, maintain path-column conventions, or remember which jobs must download bytes.
A blob column can stay a column. Lance Core owns the Blob V2 layout at the format layer, and Lance Spark owns the reference path through Spark. The target table still gets real Blob V2 data; bytes materialize on write where the connector and Lance Core have the context to do the right thing.
For multimodal Spark pipelines, this is late materialization in practice: references through the plan, bytes on write.



